魔搭社区上线“源2.0”大模型chat体验接口!
近日,浪潮信息开源可商用的大模型“源2.0”全面上线魔搭社区,并将持续在社区进行模型版本迭代更新。
目前,用户可在魔搭社区下载102B、51B、2B三种参数的“源”大模型最新版本,也可以使用魔搭社区提供的Yuan2-2B-Janus-Chatbot体验接口,直接体验“源”2B大模型能力。同时,在魔搭社区可以使用云算力对“源”大模型进行快速开发和部署。

(注:命名中hf代表Huggingface格式,Janus为最新版本名)
魔搭社区针对“源”大模型提供了模型的部署、推理和微调的最佳实践,供开发者参考。
GitHub开源地址:
https://github.com/IEIT-Yuan/Yuan-2.0
ModelScope模型开源地址:
https://modelscope.cn/models/YuanLLM/Yuan2-2B-Janus
ModelScope创空间源chat体验地址:
https://modelscope.cn/studios/YuanLLM/yuan/summary
小模型有大能量
在魔搭创空间,CPU就可以运行host Yuan2-2B-Janus-Chat模型。
Yuan2-2B-Janus-Chat模型虽然尺寸小,但是已经具备比较好的文学创作能力:

常识问答能力:
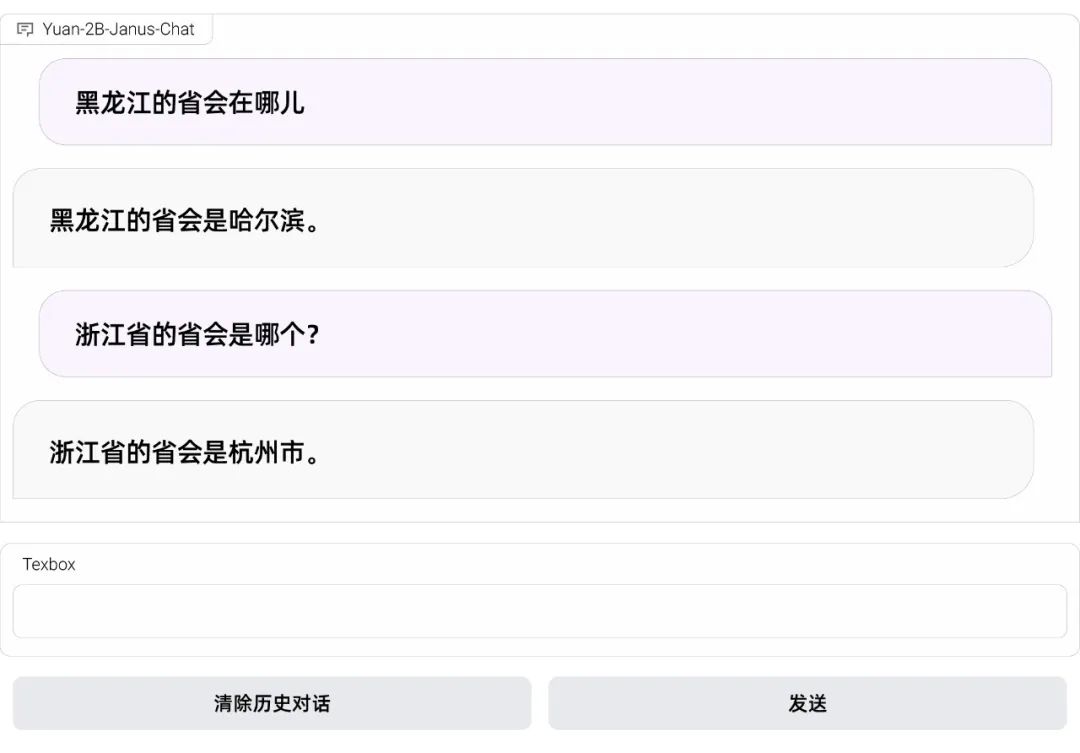
数学计算能力:

代码能力:



模型推理
在ModelScope社区的免费算力上可以实现Yuan2-2B-Janus-hf模型的推理
模型链接:
Yuan2-2B-Janus-hf:
https://modelscope.cn/models/YuanLLM/Yuan2-2B-Janus-hf/summary
推理代码:
import torch
import os
from modelscope import AutoModelForCausalLM, AutoTokenizer
print("Creat tokenizer...")
tokenizer = AutoTokenizer.from_pretrained('YuanLLM/Yuan2-2B-Janus-hf',
add_eos_token=False, add_bos_token=False, eos_token='<eod>')
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
model = AutoModelForCausalLM.from_pretrained('YuanLLM/Yuan2-2B-Janus-hf',
device_map='auto', torch_dtype=torch.bfloat16, trust_remote_code=True)
inputs = tokenizer("请问目前最先进的机器学习算法有哪些?",
return_tensors="pt")["input_ids"].to("cuda:0")
outputs = model.generate(inputs,do_sample=False,max_length=100)
print(tokenizer.decode(outputs[0]))
显存占用:
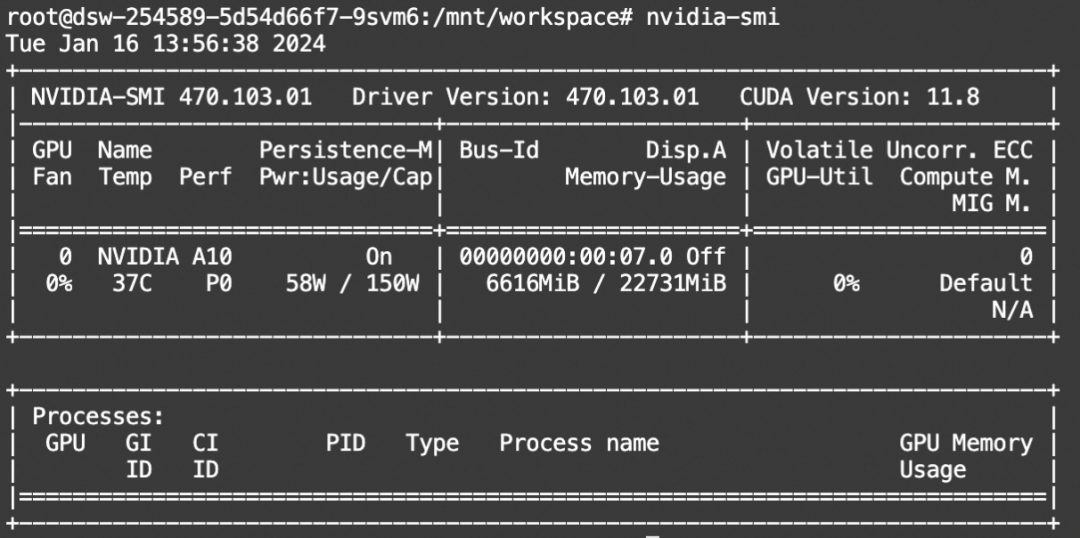
模型微调
使用SWIFT对 Yuan2-2B-Janus-Chat 进行微调, 解决分类问题。
我们使用的数据集hc3-zh包含了给定问题的人类-ChatGPT回答文本对, 通过这个数据集,可以训练一个区分对应回答是来自人类还是ChatGPT的分类模型。
代码开源地址:
https://github.com/modelscope/swift
微调脚本:
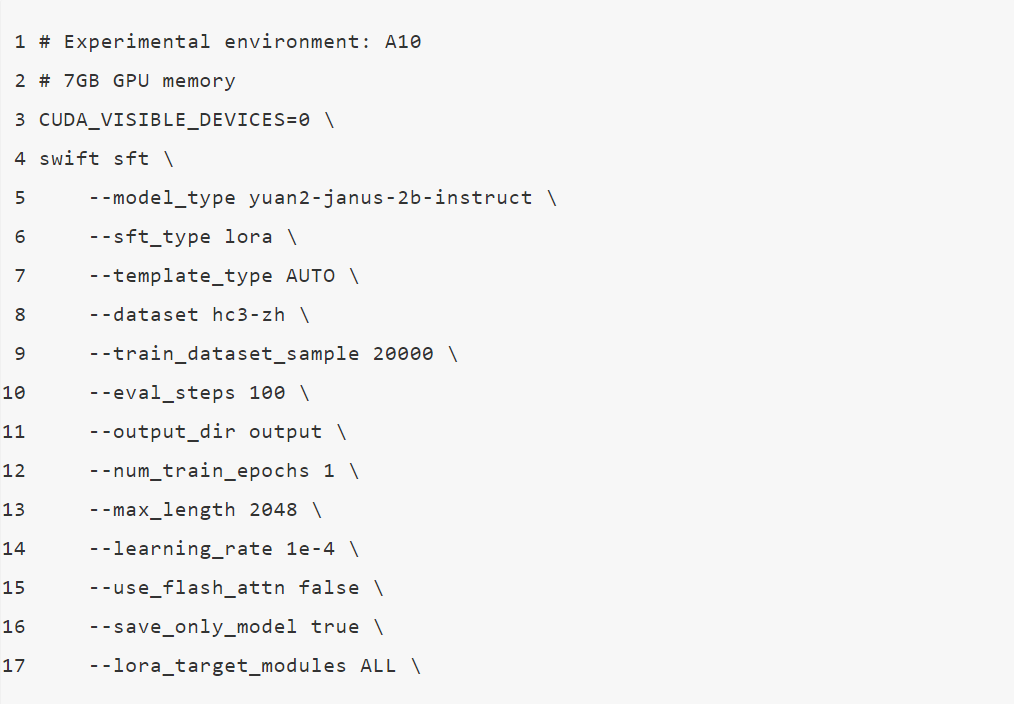
训练过程也支持本地数据集,需要指定如下参数:

自定义数据集的格式可以参考:
https://github.com/modelscope/swift/blob/main/docs/source/LLM/自定义与拓展.md#注册数据集的方式
微调后推理脚本: (这里的ckpt_dir需要修改为训练生成的checkpoint文件夹)
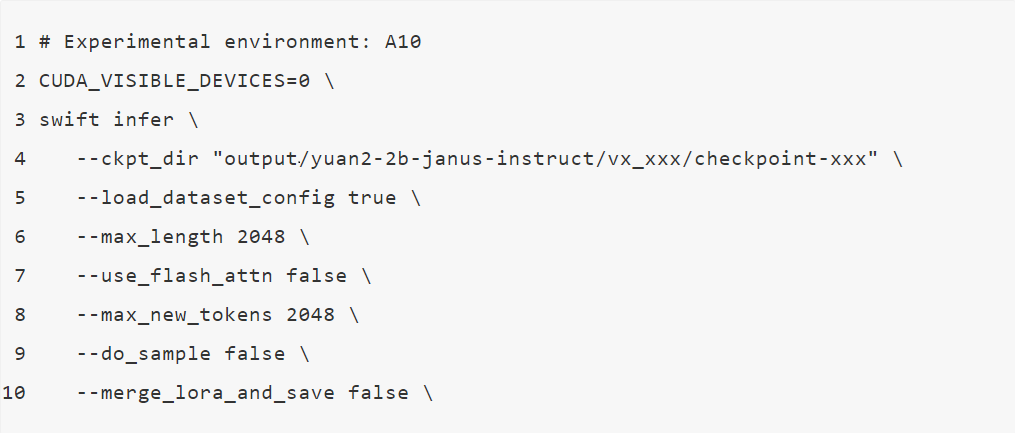
微调后生成样例:
样例1:模型正确区分QA中的回答内容由ChatGPT生成

样例2:模型正确区分QA中的回答内容由Human生成

-
2025-03-06
-
2025-03-05
-
2025-03-04
-
2025-02-27
-
2025-02-26