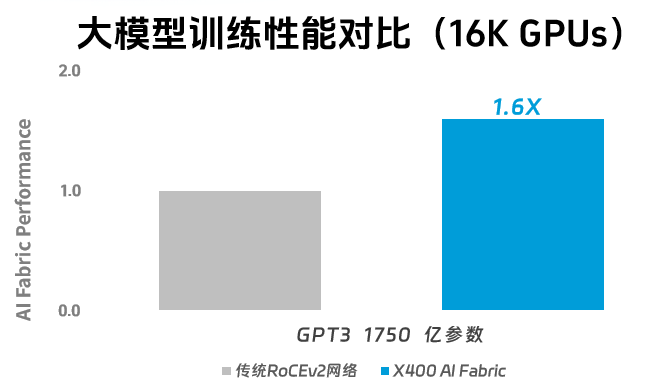
01. 超高性能 带宽利用率提升至95%并降低长尾时延
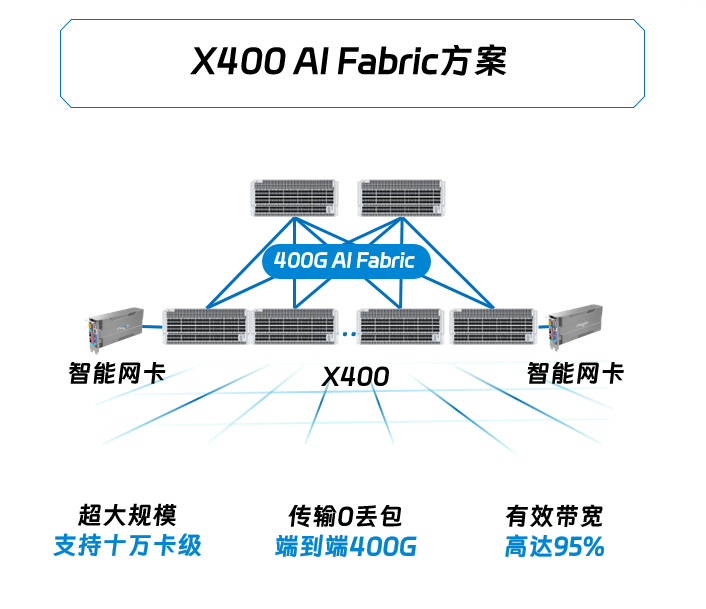
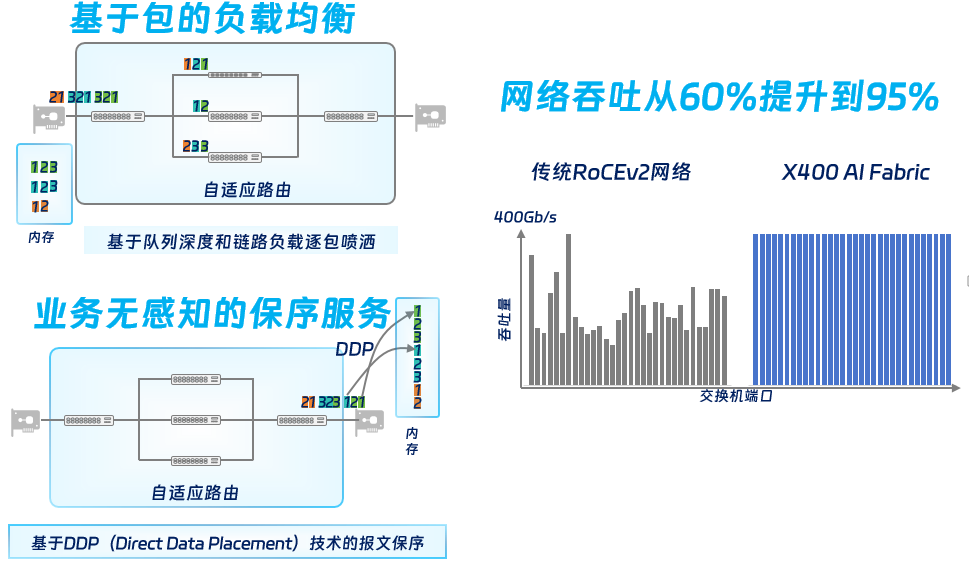
网络性能是核心,也是满足AI大模型训练的基础。X 400超级AI以太网方案采用了X400加智能网卡的协同调度,通过自适应路由、报文保序、可编程CC等技术,实现交换机和网卡更加紧密的配合,为AI大模型提供零丢包、无阻塞的全链路交换网络,机间互联性能400G,有效带宽从传统的60%提升到95%,性能达到传统RoCE的1.6倍。
网络侧:传统的ROCE方案在进行转发路径选择时采用静态hash计算方法,没有考虑路径负载状态,导致多条流可能选择相同的路径,从而导致了数据包的堆积,降低了网络吞吐率。X400在交换机侧采用包喷洒技术,提供基于数据包的细粒度路由调度,在网卡侧提供保序服务,实现构建整体端到端的无阻塞网络,相比于传统的RoCE方案仅在交换机上进行路径选择和拥塞控制的方式,将彻底改善网络流量的负载均衡问题,全面优化流量的路径分布。
端侧:包喷洒会带来一个新的问题,就是一个流里的若干个数据包,可能会选择走不同的路径,导致数据包到目的端可能会乱序,如何将乱序到达的数据包重新编排、纠正,则依赖于智能化网卡的保序服务,通过DDP(直接数据放置)技术实现乱序重排,再转发给上层协议,通过这两个技术的叠加,结合X400感知本地、远端链路负载状态,实时调整转发路径,最终使得在上层协议对乱序无感的情况下,有效带宽大幅提升。
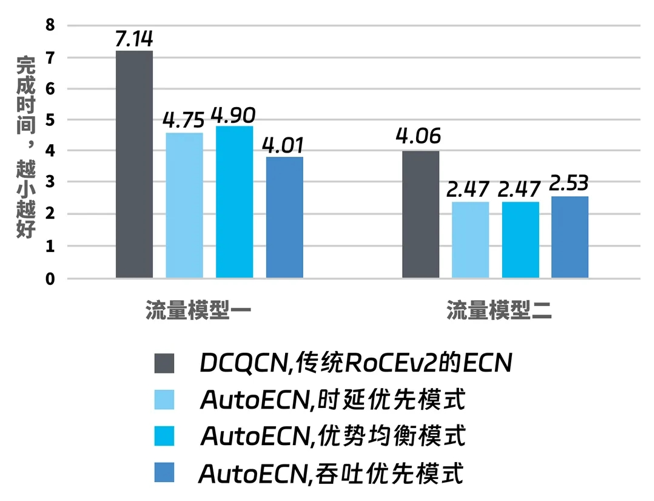
同时,浪潮信息凭借独有的Auto ECN拥塞控制技术,降低长尾时延。创新性的将人工智能技术引入到ECN调优算法里,采用两百万组的流量模型,覆盖主流的大模型训练流量特征,来对ECN神经网络算法进行训练。Auto ECN技术可以结合链路的拥塞状态,网络拓扑和长短流的实时状态进行动态的参数调整,提供拥塞控制最优解,整体缩短30%的FCT,最大化GPU的利用率。
此外,AI大模型训练的网络优化离不开NCCL通信库支持,X400和IB一样,天然的与NCCL无缝衔接,能够为大模型提供最高的性能,而其他交换方案需要对NCCL通信库进行修改和优化。
基于以上核心技术,X 400超级AI以太网方案通过在256卡GPU的训练场景下实测,在多项核心指标上显著优于传统RoCE:
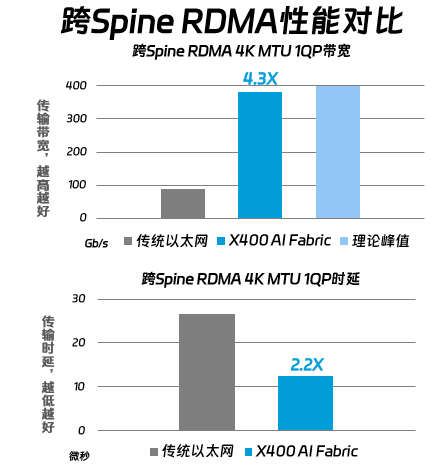
在RDMA跨Spine 4K MTU 1 QP性能测试中, X400 AI Fabric的带宽性能是传统以太网的4.3倍,接近理论峰值。同时,延迟方面,延迟比传统以太网低了2.2倍。这意味着X400 AI Fabric在数据传输和处理速度上远超传统RoCE,更适合构建超大规模的算力系统;
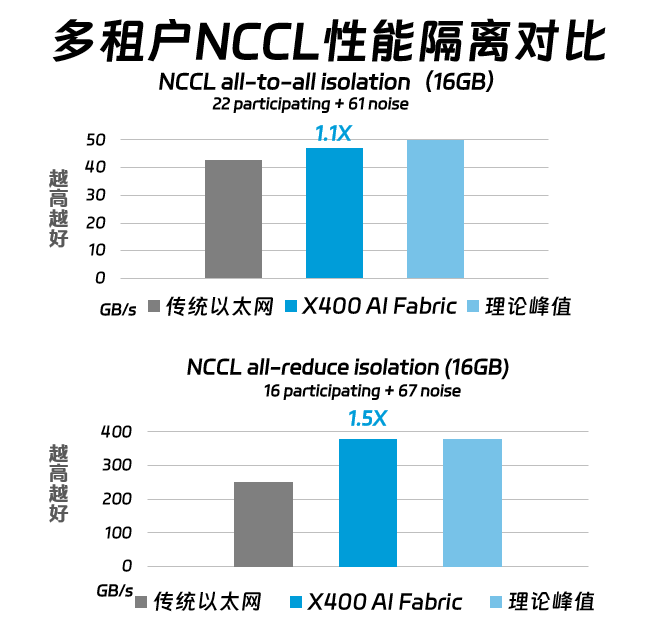
在智算中心的多租户环境下,测试NCCL all to all和all reduce的隔离性能,X400 AI Fabric分别表现出1.1倍和1.5倍的性能提升。这对于需要高效通信和数据同步的AI训练任务来说,显得尤为重要;
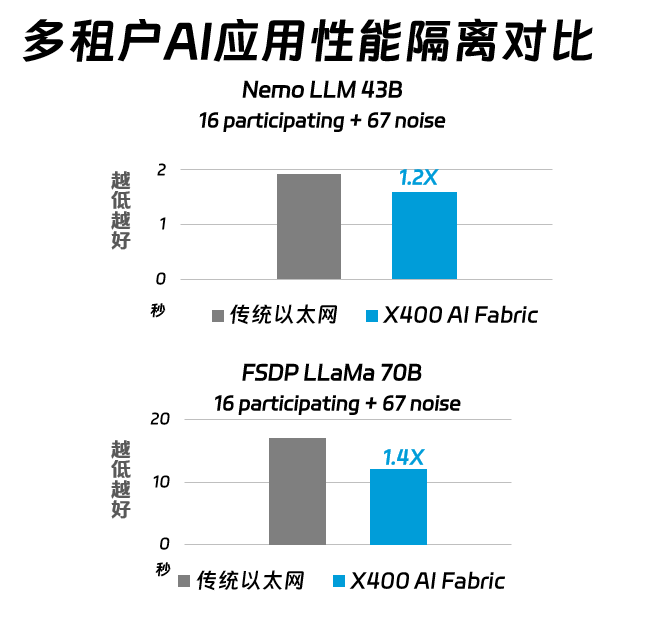
在多租户AI应用的性能隔离测试中,使用Nemo LLM 43B模型和FSDP LLAMA 70B模型时,X400 AI Fabric的迭代时间分别比传统RoCE快1.2倍和1.4倍。这意味着我们可以更快地完成训练任务,更快的获得训练成果。
总的来说,X 400超级AI以太网不仅在带宽和延迟上远超传统以太网,更是在大规模算力群和复杂的多租户场景中保持了卓越的性能表现,大大加速了AI模型的训练过程,充分释放客户构建的算力系统价值。
02. 超大规模 算力资源灵活拓展支持数十万卡
伴随着生成式AI的迅猛发展,模型参数量急速膨胀,单个CPU、GPU甚至多个GPU上无法完成模型训练的挑战。为此,智算中心通常会采用分布式训练技术,对模型和数据进行切分,采用多机多卡的方式训练,通过构建数以万计的GPU系统来提升算力,大幅缩短训练周期,这就需要智算网络能够具备支持大规模GPU 服务器系统的能力,提供高性能、灵活可拓展的网络服务,以满足未来不断变化的GPU通信负载需求。
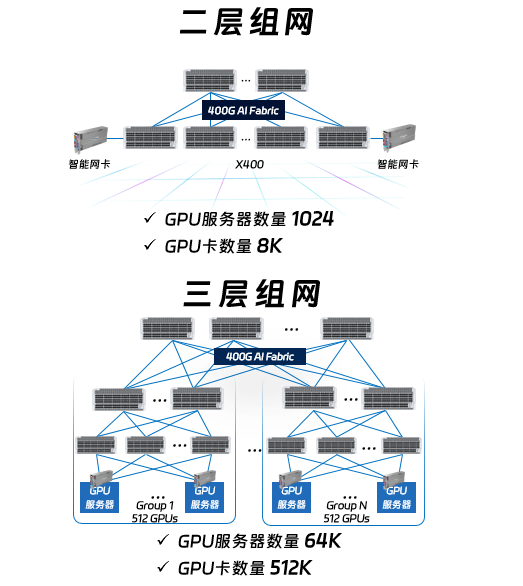
X400超级AI以太网在超高的端口密度以及弹性可拓展的能力加持下,具备超高性能的同时,可以满足数十万卡级别的算力规模,在二层组网下,GPU服务器数量可达1024台,支持8K张GPU卡,可根据算力规模灵活拓展到三层组网,GPU服务器规模可达64000台,最大支持GPU卡的数量可以达到512K张,满足各种规模的组网要求,灵活的弹性组网成为业务创新的强大助力。
03. 超高可靠 确保业务极致稳定
大模型训练的稳定性至关重要,根据专业分析机构semianalysis显示,超十万卡的 GPU因网络链路故障导致的模型训练重启所花费的时间,将比模型训练本身所花费的时间更多,因此企业难以接受网络导致的业务中断,只有稳定可靠的网络才能满足AI场景的苛刻要求。为此,浪潮信息集成了系统级的高可用技术,全方位保障AI网络的极致稳定。
在硬件层X400集成了IGE智能防护单元,对关键部件器件进行冗余备份,对关键硬件信号进行全面的监控和故障隔离,确保硬件层面高可靠,由于电子元件都难以避免老化和性能衰减,通过提供高速链路级的性能衰减预警,对Serdes关键参数定期检查,提前预警高速链路性能可能出现的劣化或者故障,发送提醒,避免链路的突然中断影响业务;
通过集成的网络监控模块,以及多种高精度的遥测技术,如buffer、Congestion、日志等,X400实现芯片级、系统级以及链路完整的监控,可以监控到底层链路的状况拥塞,二三层转发状况,整个包转发延时的变化,甚至包括RDMA任务链路的变化,全面掌握AI节点间通信状态;
结合以上监控的数据,通过路径重选机制,X400可以对潜在的故障链路进行自动隔离,在上层应用无感的情况下实现故障自愈。对于小概率出现的链路故障,如果是本地链路上行,可以通过硬件感知进行亚毫秒级的路径切换;如果本地下行链路故障,采用快速重路由技术,自动切换到备份路径上,时间上略慢于上行链路故障;如果发生远端负载断链,需要在更远侧对路由进行调度和均衡,通过在BGP协议优化多项设置,将整个链路恢复时间缩短到毫秒级,整体上无论哪种链路故障均可以实现毫秒级的故障自愈。
04. 极致体验 提升整体运营效率
随着算力资源的不断投入,需要管理和配置的网元设备不断增加,基于传统RoCE方案的网络建设,涉及一系列繁杂多样的配置,错误的配置导致的训练性能下降,意味着业务上线以及运营维护的难度陡增,而且省心的方案往往带来成本飙升,业务尚未开展就困难重重。
为此,浪潮信息X400超级AI以太网方案延续了以太方案的兼容性和性价比,确保敏捷运维和超高性能的同时,大幅降低网络建设TCO,并为客户打造一键式自动化的部署模式,实现模型特征自适应的网络配置,将部署周期从数周缩短至数天,加速业务上线,结合全面可视的智能运维平台,直观发现潜在风险与故障,保证业务的连续性。
浪潮信息基于Spectrum-X平台打造的X400超级AI以太网解决方案,为智算中心客户带来三大核心价值:速度、效率和经济性,全面优化业务体验。该方案凭借其超高性能,支持万卡超大规模无损网络,实现算力资源的最大化利用,并具备多重可靠技术,确保算力资源高可用保障大规模模型训练和推理业务能够高效稳定不间断地运行。此外,该方案通过其卓越的成本效益,助力客户大幅提升投资回报,实现成本与效益的完美平衡,为智算中心客户打造更快、更好、更省的网络业务体验。

 第八代服务器
第八代服务器