夺冠方案详解!CVPR全球自动驾驶挑战赛之浪潮信息F-OCC算法
近日,在全球权威的CVPR 2024自动驾驶国际挑战赛(Autonomous Grand Challenge)中,浪潮信息AI团队所提交的“F-OCC”算法模型以48.9%的出色成绩斩获占据栅格和运动估计(Occupancy & Flow)赛道第一名。
本篇文章将根据浪潮信息提交的技术报告“3D Occupancy and Flow Prediction based on Forward View Transformation”,详解其使用的模型架构、优化措施和实验结果。
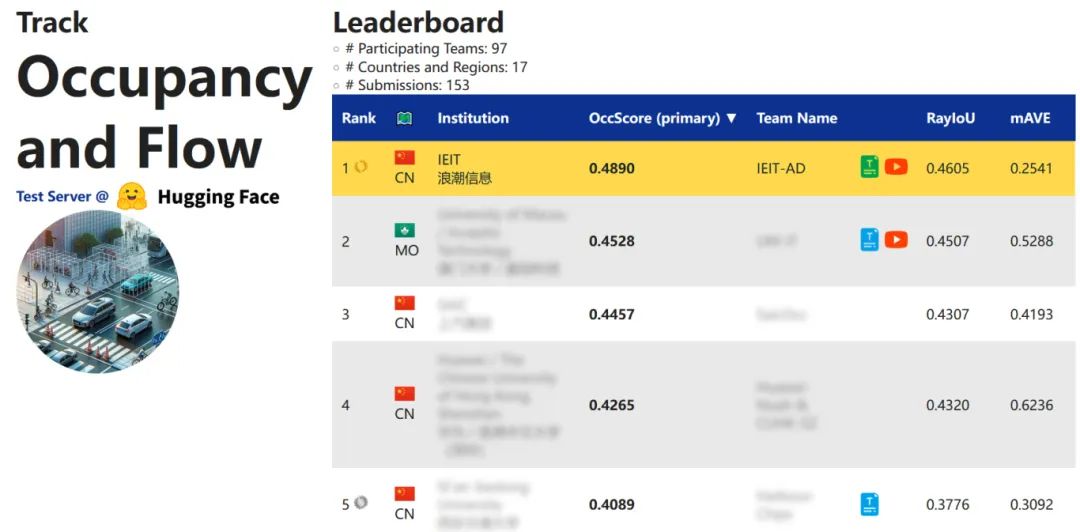
图1 浪潮信息AI团队斩获占据栅格和运动估计赛道第一名
背景与挑战
3D场景感知在自动驾驶系统中扮演着非常重要的角色。当前城市道路交通环境中,道路布局复杂、交通参与元素多样,对自动驾驶感知任务提出了极大的挑战。传统的三维物体检测方法使用3D框来描述物体的位置、大小和方向,缺乏对物体复杂几何形状的详细描述。同时,此类方法大多只关注目标物体,如车辆、行人、自行车等,缺乏对路面、人行横道、建筑物等静态交通元素的检测。占据栅格是一种新的自动驾驶场景表示,其将车辆周围3D空间进行体素化,并对每个立体网格添加占据、语义和运动信息。占据栅格预测需要对3D空间中的每个体素的占据信息和语义标签进行预测,为自动驾驶系统提供更精细、全面的场景感知信息,以提升自动驾驶系统在复杂场景下的安全性和可靠性。

图2 Occupancy and Flow示意图
基于相机数据的3D场景感知框架可以大致分为三类:第一类是以LSS和BEVDet为代表的前向投影方法,这类方法利用相机内参、外参数据,将图像特征通过估计的图像深度信息,投影到以车辆为中心的3D空间,并进行体素化以得到3D特征;第二类是以BEVFormer为代表的逆向投影方法,其首先在3D空间中构建查询点,然后通过相机内参和外参将查询点投影到2D图像特征空间,以获取对应的图像特征信息;第三类是以FB-OCC为代表的双向投影方法,这类方法融合上述两种方法来构建3D特征。
方法介绍
整体架构
F-OCC模型采用了前向投影框架以兼顾准确度与运行效率。首先,多摄像头数据通过图像编码网络,得到2D图像特征。然后,深度预测网络利用2D图像特征估计每个特征点的深度信息。利用估计的深度信息,模型将图像空间中的2D特征投影到以车辆自身为中心的3D空间,并进行体素化。3D编码网络对得到的3D特征进行特征增强,以提升其表征能力。最后,检测网络输出3D空间中每个点的占据信息、语义标签和运动信息预测。图3为F-OCC的模型架构图。
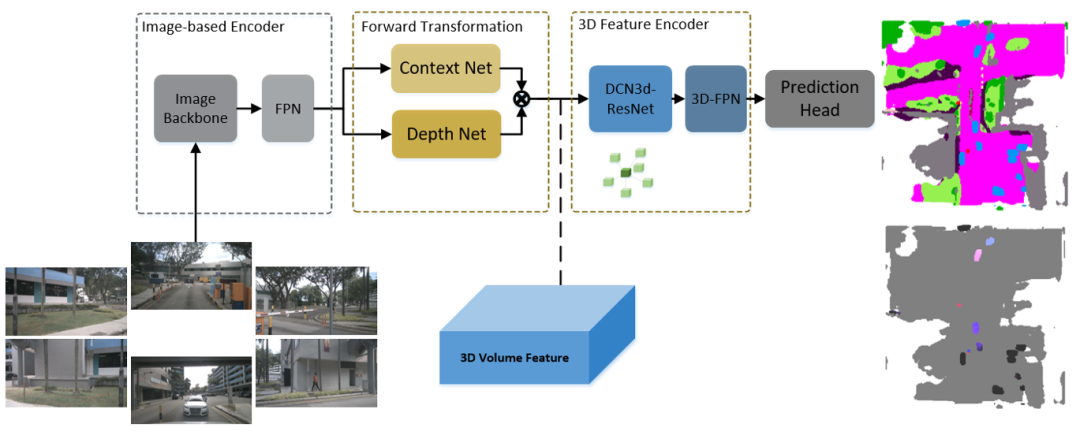
图3 模型架构图
(右上:不同颜色表示不同类别的体素,右下:颜色代表速度方向,亮度代表速度大小,背景体素为灰色)
优化措施
1>数据预处理

图4 掩模生成过程示意图
(左:原始真值示意图;中:模拟激光射线示意图;右:掩模后真值示意图)
本次挑战提供的训练数据中,很多相机无法直接观测到的体素点也被标记了语义信息,例如,被其它物体遮挡的体素、物体内部不可见的体素。这些体素数据在训练过程中,会对基于相机数据的预测网络的优化产生干扰。参考SparseOcc,本方法对真值数据进行掩模处理。如图4中间子图,在训练过程中,根据车辆行驶轨迹模拟多个LiDAR发射点,并在每个发射点模拟生成多束激光射线,每束激光射线终止于触碰到的第一个有语义信息的体素。激光射线触碰的占据体素和与发射点之间的非占据体素标记为True,其余的体素点标记为False,以此生成真值体素的掩模标签。训练过程中,只用掩模标记为True的体素进行模型训练,忽略掉标记为False的体素点。图4右图展示了掩模后的有效体素。可以看到,在模型训练中,遮挡的点或者物体内部的点,没有参与模型的训练。

图5 掩模示意图与改进
模型预测过程中,3D感知区域边缘会出现很多错检点。原因之一是在掩模生成过程中,忽略了部分感知区域边缘的体素信息。推理过程中,由于深度估计的误差,部分检测范围外的物体特征映射到了检测区域内,导致错检。基于这种考虑,我们对掩模生成方案进行了优化,在检测范围的边缘附近随机添加了20%的体素点,参与模型训练。优化前后的有效体素可视化如上图右侧所示。优化后,模型的Occ_score从0.32提升到0.34。
02>图像基础网络
图像编码网络的性能对整个模型的预测精度非常重要。考虑到模型的运算效率和预测精度寻求,我们选择FlashInternImage系列的图像编码模型作为模型的图像编码网络。这种网络优化了InternImage网络中的DCN算子,提升了模型的检测速度和检测精度。在测试实验中,我们使用了FlashInternImage-Tiny和FlashInternImage-Large进行测试。在最终版本中,我们使用了FlashInternImage-Large,其包含了大约220M的模型参数。
03>可形变3D卷积
图6 可形变3D卷积示意图
相比于传统的卷积操作,可形变卷积具有较大的感知范围和较强的编码能力,其在图像检测任务上展示了较强的性能。本模型将可形变卷积算子DCNv4在3D特征上进行了拓展。在3D体素特征编码模块中,传统的3D卷积算子替换为可形变3D卷积算子,提升了模型的整体检测能力。为提升模型的运算速度、降低模型的显存消耗,我们使用CUDA对DCN3D进行了实现与优化。相较于Pytorch版本,CUDA实现版本提升了模型的运算速度,同时降低了显存消耗。
实验结果
表1 不同设置下的占据栅格和运动预测表现
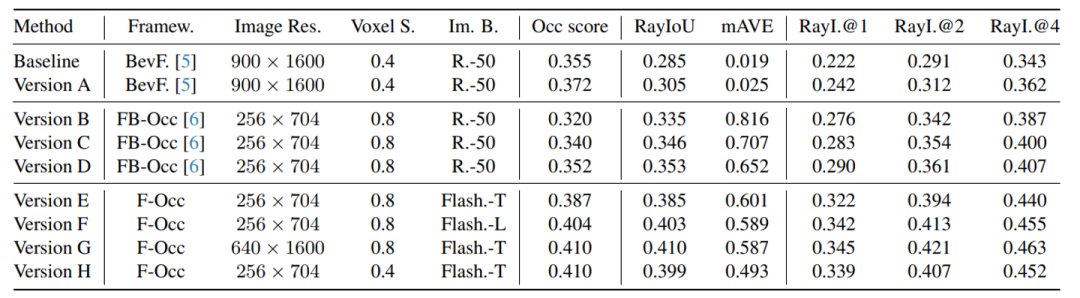
为验证优化措施的有效性,本文在Validation数据子集上进行了消融实验,结果如上图所示。
Baseline为官方提供的基于BEVFormer的预测模型。Version A中,我们在基础模型的训练中添加了可视化掩模的数据预处理。为降低类别不均衡,这两种方法中,我们在非占据的体素中随机挑选了20%参与训练。在Version B到Version D的实验中,我们以FB-OCC为框架,测试了掩模和DCN3D的有效性。其中,Version B使用初始的掩模数据进行训练,Version C使用改良的掩模数据进行训练。Version D中,我们将3D体素编码中的传统3D卷积算子替换为DCN3D算子。通过结果可见,基于掩模的数据预处理和DCN3D都可以提升模型的检测精度。Version E中,我们采用了前向投影架构,并将Image backbone替换为FlashInternImage-Tiny。在version F、G、H中,我们分别测试了骨架网络、图像尺寸和体素分辨率对预测结果的影响。通过表格可见,提升图像估价、图像尺寸和体素分辨率可以提升模型的检测性能。
最终提交结果的模型骨架为F-Occ,基础网络为FlashInternImage-L,图像尺寸为1600x640,体素分辨率为0.4m。最终综合Occ得分为0.489。在检测头中,Flow预测分支与Occupancy预测分支的网络结构相似。后处理过程中,在输出Flow预测结果前,我们对预测的Flow估计进行了处理。我们将所有占据网络预测分支中估计为背景(非前8类)或者Free的体素对应的Flow值设置为0。模型没有进行TTA(test-time augmentation)和模型集成的操作。
总结
本文介绍了获得占据栅格和运动估计赛道第一名的“F-OC”算法模型。模型通过数据预处理、图像基础网络筛选、算子优化等措施,提升了对占据栅格和运动估计的检测能力。
参考文献
[1] Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Proceedings of the European Conference on Computer Vision, 2020
[2] Junjie Huang and Guan Huang. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. ArXiv 2022
[3] Yuwen Xiong, Zhiqi Li, Yuntao Chen, Feng Wang, Xizhou Zhu, Jiapeng Luo, Wenhai Wang, Tong Lu, Hongsheng Li, Yu Qiao, et al. Efficient deformable convnets: Rethinking dynamic and sparse operator for vision applications. ArXiv, 2024
[4] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-cameraimages via spatiotemporal transformers. ECCV, 2022
[5] Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, and Jose M Alvarez. Fb-occ: 3d occupancy prediction based on forward-backward view transformation. ArXiv, 2023
[6] Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, and Limin Wang. Fully Sparse 3D Occupancy Prediction. ArXiv 2023
[7] Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. CVPR, 2023
-
2025-03-06
-
2025-03-05
-
2025-03-04
-
2025-02-27
-
2025-02-26