大模型火了,参数规模一路狂飙,在新的超级AI算力系统背后,多层次的交换机网络也让网工朋友很是头疼。
网工朋友可能还没注意到,最近市面上有一款吊炸天的“大模型专用交换机”来了。

毕竟,交换机这种通用网络产品发展了几十年,时至今日,任何网络技术,很难撩起人们的兴奋点。
但,仔细了解一下,这款交换机,着实让人兴奋。
甚至可以说,这是国内目前AIGC领域最牛交换机。
为什么这么高评价?我们看看实测吧
这款叫做X400的交换机,端口规格是128×400G,看起来似乎“平平无奇”。

因为业内同行们,也差不多是这个规格(单芯片51.2T方案,64×800G或128×400G)。

可是,类似的规格,这款交换机却表现出“吊打”同行的能力。
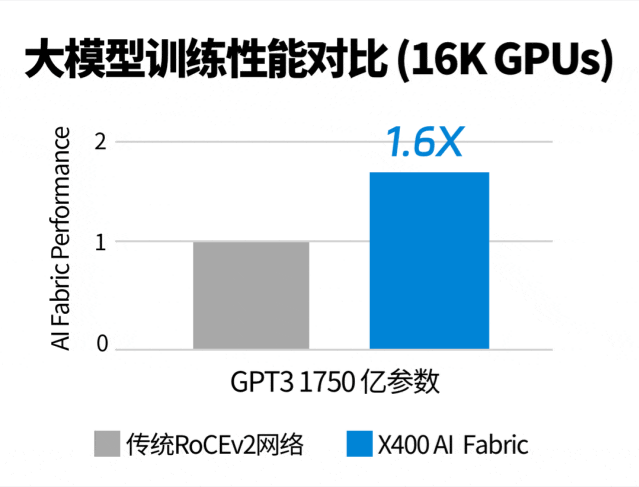
跟同行们的51.2T方案相比,用这款交换机组网训练大模型,训练性能可以提升至1.6倍。

下面这个实测就很能说明问题:
16000张GPU卡环境,训练1750亿参数的GPT3,X400交换机吊打传统RoCE网络。
这是什么概念呢?
这意味着,基于X400交换机构建的以太网,大模型训练性能可以完全对标同速率的IB网络。
你花着以太网RoCE的钱,买到的却是与IB网络相当的性能!

接下来,我们就讲讲,这个看似平平无奇的X400,凭啥这么猛?
首先,这是国内目前唯一量产的基于Spectrum-4交换芯片的交换机。接
当前市面上51.2T交换芯片方案四分天下:Spectrum-4、Tomahawk 5、Silicon One G200以及Teralynx 10,每一家都各有特色。

国内数通大厂和互联网巨头们,纷纷发布了51.2T交换机,大多搭载的是Tomahawk5方案,而这款X400交换机,是首款采用Spectrum-4的。
懂的都懂,Spectrum-4在AI场景能力超强。
相比其他方案,Spectrum-4具备一些独特的优势,专门应对AI业务场景:
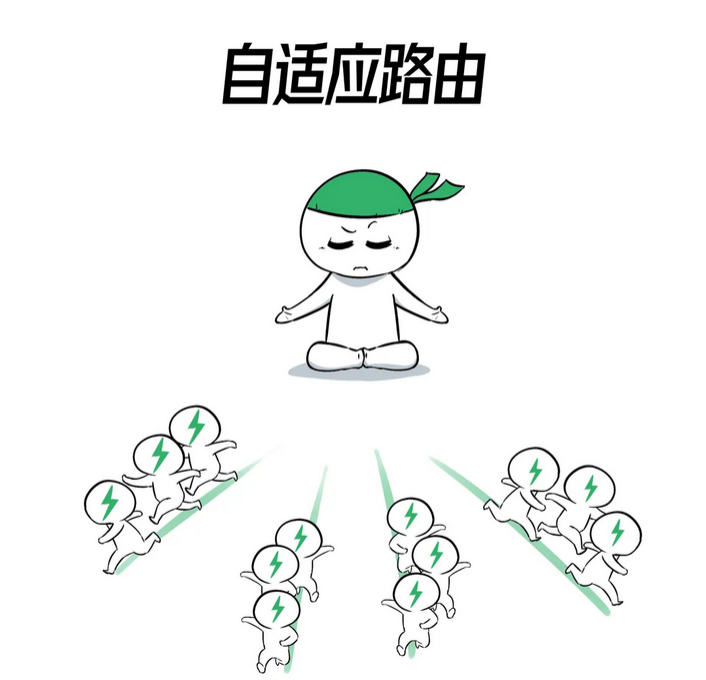


❶自适应路由实现完美负载均衡 ❷多租户流量隔离,互不打扰 ❸交换链路带宽利用率高 ❹训推任务实现低延时,低抖动和低尾延时。
更为重要的是,AI大模型大多基于GPU构建,训练的网络优化离不开NCCL集合通信库支持。
X400和IB一样,与NCCL天然无缝衔接,而其他交换方案需要对NCCL进行额外修改和优化。

所以,在硬件底子上,X400交换机天生就「骨骼精奇」,赢在了起跑线上。
不过,硬件能力只决定了交换机的下限,软件能力才能拉高交换机的上限。
X400在软件上,针对AIGC场景进行了特别优化。
这么说吧,同样是RoCE,X400能吊打传统RoCE交换机,软件层的优化,功不可没。
AUTO ECN技术
搞过数据中心网络的都知道,在对网络延迟和丢包比较敏感的场景,通常都会启用ECN技术,现在市面上用的比较多的叫做“DCQCN”。
ECN是一种网络拥塞通知和管理机制,它在监测到网络中即将发生拥塞的时候,不会将报文丢弃,而是添加拥塞标记,让发送方动态调整拥塞控制窗口(CWND),从而避免拥塞。
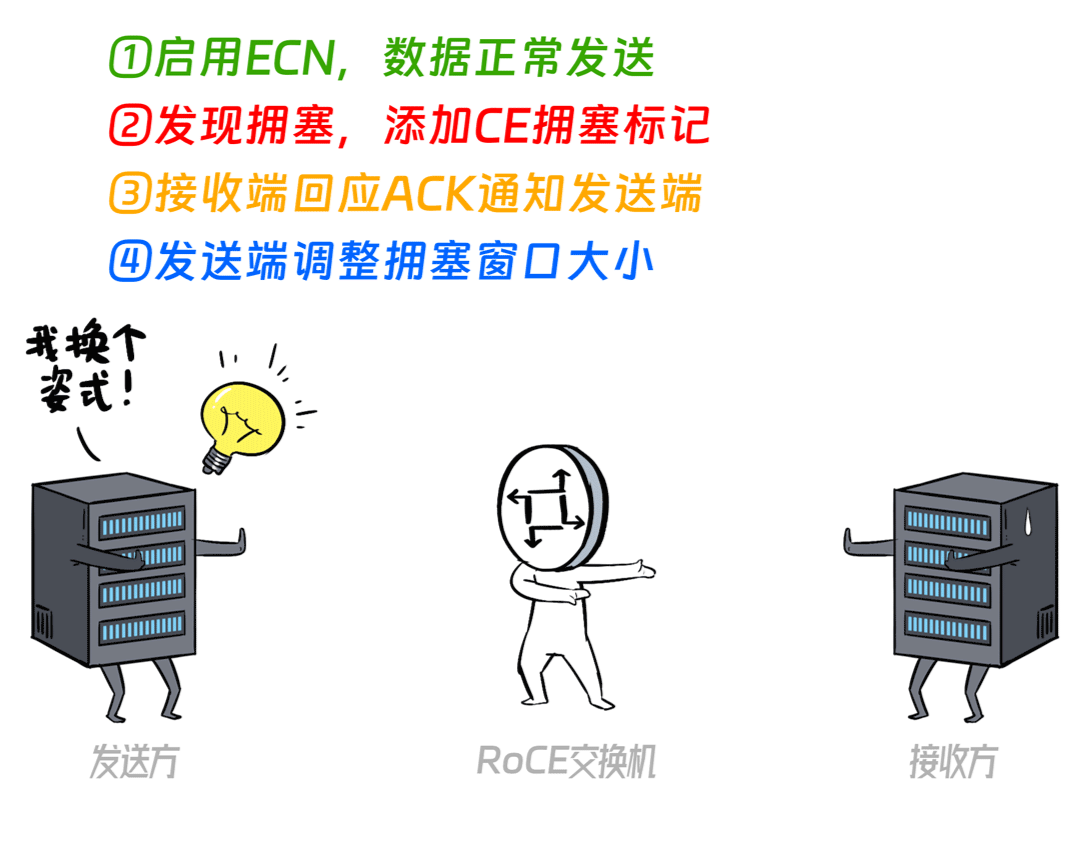
说白了,快要拥塞的时候,就通知发送方步子迈小点儿,没有拥塞的时候,步子就迈大点儿。

但是呢,这个“步子”的大小(拥塞窗口大小)是非常有学问的,步子太大容易扯着蛋,步子太小就会影响吞吐量。
能够动态地找出那个最优的“窗口”,既保证不拥塞,又有最高的吞吐量,深深困扰了广大数据中心网工们。

手动ECN调优太麻烦了,X400交换机是怎么干的呢?
这家伙鬼的很,它要用AI的办法来解决AI问题,搞出了一个AutoECN的算法,相当于每台交换机都内置了一个流量调参大模型。

在实际流量环境中,X400交换机会实时采集流量特征,并通过带外管理口进行上下游流量特征同步(这种同步不会占用带内带宽资源)。
被采集到的流量状态会作为输入,给到交换机内置的AutoECN模型,然后模型会根据输入,完成实时推理,得到此时最优的ECN参数,实时设置。

跟传统的ECN/DCQCN相比,AutoECN的拥塞控制阈值是一个完全动态调整的最优值,也不怕由于CNP报文发送不及时导致的控速失效。
来看一下实战效果
同样一组流量,在启用了DCQCN和AutoECN的交换机上传输,后者对传输效率的改进非常明显。
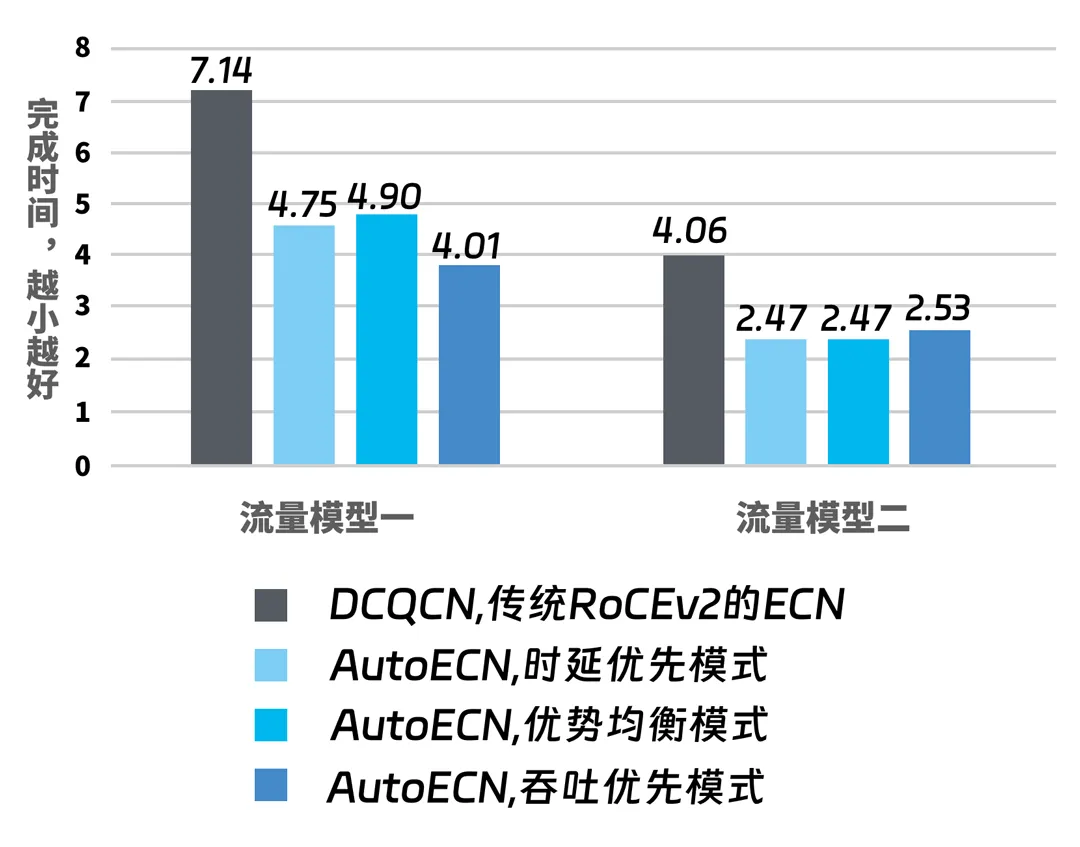
如上图,AutoECN提供了三种模型:时延优先、吞吐优先、均衡模型。然后分别用两种特征的流量来打,每种模型的表现,都大幅超过传统ECN(传输每一组流量时,所用时间越短越好)。
当你的业务更挑时延,就用时延优先模型,如果更偏向吞吐,就用吞吐优先模型,如果两种都想兼顾,那就用均衡模型。
总之不管流量多变态,AutoECN总能基于AI技术,动态调参,给出一个最优方案。

RTT-CC拥塞控制
如果你的业务对网络延迟格外敏感,希望更低的延迟和抖动,基于X400交换机构建的AI Fabirc方案还额外准备了一项秘技:RTT-CC。
RTT-CC不需要像ECN那样对拥塞数据包进行显式标记,而是通过持续监控和评估数据包的往返时间,预测网络拥塞。
X400 AI Fabirc方案的RTT-CC功能,采用了基于硬件的反馈环路,动态监测拥塞并实时调整发送窗口大小和速率,性能更好,时延表现更优。
如此,同时具备RTT-CC和AutoECN的拥塞控制技术,可以更好地满足低延迟、高吞吐、零丢包的严苛场景需求。

逐包负载均衡
在数据中心网络中,涉及到多路径传输的时候,传统RoCE方案通常会用ECMP等技术,来实现多链路负载分担。
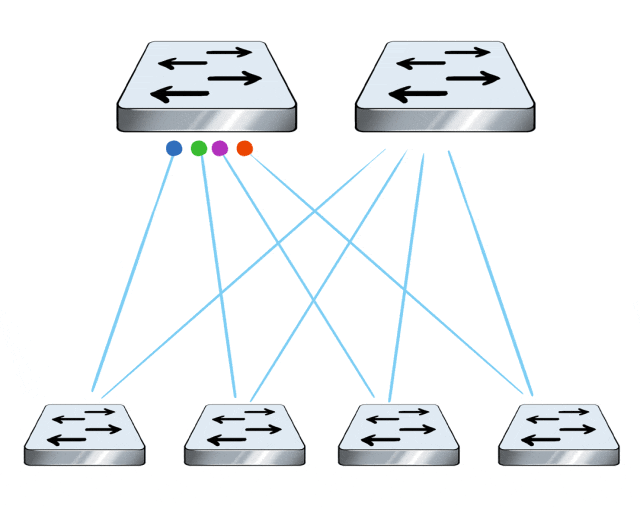
但是吧,ECMP的负载分担,是基于流的(Flow Based,根据每条流哈希值的不同,调度到不同的链路上),粒度太粗犷。
极端的情况,会因为哈希不均匀或者流的大小悬殊,导致流量都被调度到一条链路上,而其他链路没活可干,整网传输效率打折。
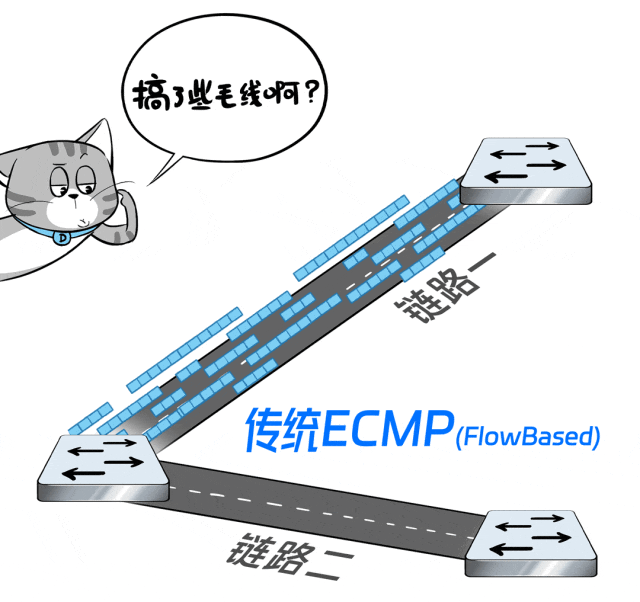
怎么破?
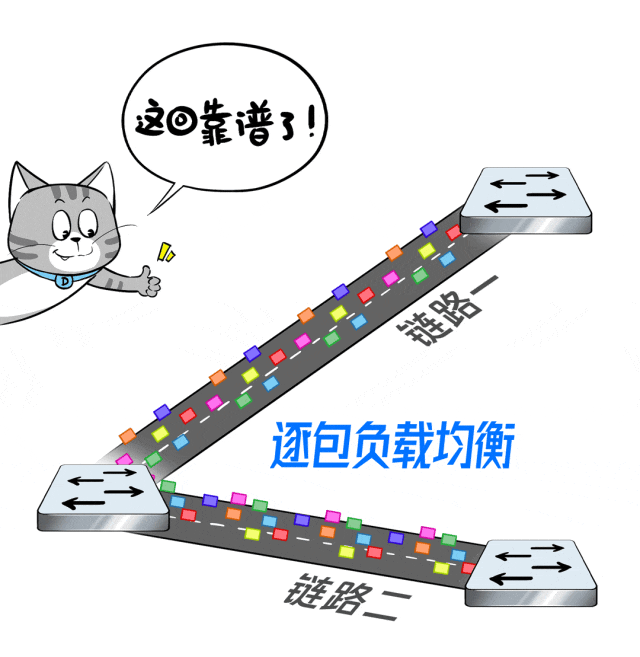
X400交换机支持自适应路由(AR)和包喷洒(Packet spraying)技术。
简单讲就是逐包负载均衡:基于每个数据包来调度,粒度更细,算法更优。
这样,让每条路都均匀负载分担,提升整网吞吐量,打满每条链路,喂饱每块GPU。
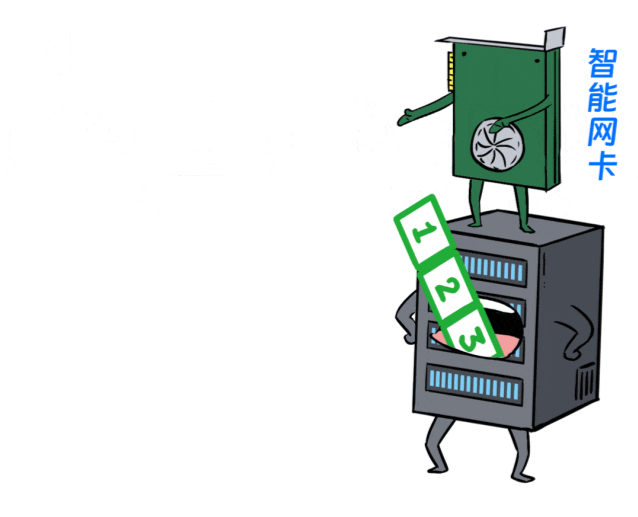
当然,这种逐包负载均衡,因为每个包走的路况不一样,到达服务器端的时候,数据包先后顺序可能会错乱,如果服务器没点特殊本事,就会吃不消。
于是,跟X400交换机配套的服务器,也配备了支持保序功能的智能网卡,可以对乱序的数据包,进行重组。
这样就完美了,既不担心乱序,又保证了链路的高效利用。
凭借这三项超能力(AutoECN、RTT-CC、自适应路由),X400交换机成功扛下了智算中心AI算力系统高效互联的严苛诉求。

不止如此,X400交换机在软件层面,还采用了大量技术来提升可靠性和可维护性。
比如故障自愈能力,IGE智能防护技术、可视化监控、ZTP部署…

同时,X400交换机遵循S3IP-UNP规范设计,支持开源SONiC和第三方网络OS,对希望构建超级AI算力系统的客户,都具备极大的灵活性。

说了这么多,这个X400交换机到底谁家的产品呢?
嘿嘿,浪潮信息。
浪潮信息X400超级AI以太网交换机,专门面向生成式AI场景打造,国内首款支持NVIDIA Spectrum-X平台技术,并基于X400和BlueField-3 SuperNICs打造端网协同的X400超级AI以太网(X400 AI Fabric)方案。

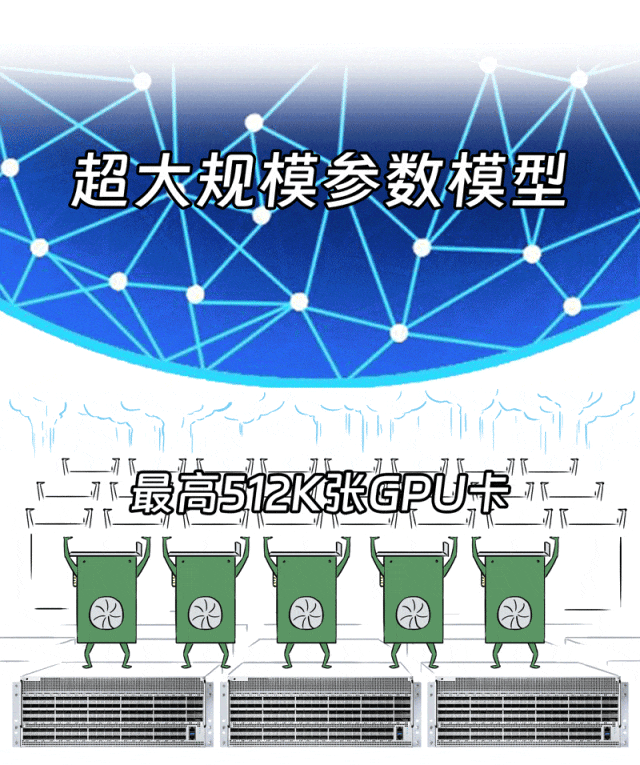
浪潮信息提供了端网协同的X400 AI Fabric方案,即插即用,最大支持512K张GPU的AI算力系统。
与业内传统RoCE组网方案相比,带宽利用率超过95%,时延降低30%,大幅提升大模型训练速度。
浪潮信息凭什么能造出性能如此拉满的AI交换机?实战效果甚至还超越了一众数通大厂的RoCE产品?
浪潮信息是国内最大的AI服务器提供商,连续7年位居第一。
同时,浪潮信息作为头部互联网客户的核心网络供应商,具备丰富的数据中心与智算中心的组网经验。

基于对AI基础设施和应用的理解以及持续深入的网络研发实践,浪潮信息发布了这款全新的超级AI以太网交换机X400,成为业界瞩目的顶流产品。

大模型时代,一切都在重塑,浪潮信息X400,筑起通往大模型的超级高速路!
(注:本文转载自科技自媒体“特大号”官微)

 第八代服务器
第八代服务器















