10PB全闪+50PB混闪!元脑服务器支撑大模型智算中心存储系统建设
2025-01-16
在AI大模型快速发展的当下,随着算力的飙升,数据存储却逐渐成为新的瓶颈。针对互联网、金融、生命科学等领域AI大模型应用在训练时涌现的PB级数据存储与处理需求,某智算中心基于元脑NF5266G7、NF5180G7等存储服务器产品,搭建了大容量、高性能、高可靠的多层存储解决方案,成功构建了50PB对象存储数据,10PB全闪文件存储数据的资源池,全闪性能可伴随节点数量增加而线性增加,存储带宽可达6TB/秒,IOPS达到亿级。面对万亿参数模型,90天的单训练周期GPU等待时间从7天减少到1天,加速释放人工智能创新潜能。

智算中心建设浪潮下,海量数据的存储成为新热点
据统计,2024年中国智算中心新建/改造项目超过196个,与智算相关的公开可见招标,超过1400个,多个城市正在推动人工智能算力新高地建设,发力智算中心建设与扩容。
以某地区智算中心为例,为加速大模型训练和推理业务赋能千行百业的创新涌现,智算中心构建了大规模GPU集群,但随着模型参数规模和数据量的激增,大规模GPU在运行中逐渐暴露出利用率较低的问题。其中一个原因就在于数据瓶颈:AI大模型训练所需的数据无法高效地传输到GPU,导致GPU计算资源出现空闲浪费。为了解决数据移动和计算效率低造成的GPU空闲问题,针对数据在不同AI负载阶段如何流转的研究,成为当前AI大模型领域的热点。
数据预处理:智算中心存储的几十甚至上百PB级规模的海量数据要转换为训练样本,需要清洗、标注、过滤等,会耗费大量计算资源和时间,但最终可能仅有小部分数据被使用,这造成了严重的效率瓶颈,需要大容量、计算能力强的存储服务器,来应对极大规模的原始数据处理。斯坦福大学、Meta公司和某超大规模云计算平台就通过研究揭示了一个重要发现:即使是在高密度GPU集群中,由于负责预处理工作负载的存储服务器无法及时供给足够的训练样本数据,GPU经常会处于空闲状态。
模型训练:训练过程中,需要将拥有万亿参数的模型和数据批次从存储加载到GPU。这涉及高效的权重和参数更新,对存储读写速度和带宽有很高的要求。同时,频繁的Checkpoint操作,也增加了存储的负担。对于一个万亿参数规模的模型,要求具备能处理数十PB级数据的强大存储基础设施,带宽至少2TB/秒的吞吐,上亿级IOPS。
模型推理与归集:推理阶段,AI大模型应用对延迟要求极高,并且通常需要处理大量并发请求,尤其在线服务、推荐系统等。AI推理后还会产生大量新的数据,包括训练数据、模型文件、日志等,这些数据的归档需要高容量、低成本的存储作为支撑。
元脑服务器构建多层存储方案,加速万亿参数模型训练
为应对自动驾驶、生命科学、金融交易、代码生成等多样化的AI大模型训练场景的数据存储挑战,智算中心采用上百台元脑NF5266G7、NF5180G7、NF5476G7存储服务器等构成的多层AI存储解决方案,构建10PB全闪文件存储和50PB混闪对象存储的AI存储资源池,为AI大模型训练提供大容量、高性能、高可靠的存储能力支撑。
在多层AI存储方案中,NF5266G7 作为数据预处理节点,业界最高存算密度,加速海量的文本、视频等异构数据到训练样本的转换效率,确保数据能够存得多且算得快,让AI大模型的数据预处理效率提升1倍以上。针对AI大模型训练的数据高吞吐需求,以NF5180G7 作全闪文件存储节点,业界最高性能并行存储服务器,32个E1.S直连存储矩阵,单机性能达到千万IOPS,无惧小文件读写难题,实现TB级训练数据Checkpoint读取耗时从10分钟缩短至10秒内。在数据归集过程中,以NF5476G7 构建混闪对象存储资源,业界领先大存储容量4U60存储服务器设计,极具存储性价比,TCO降低12%。
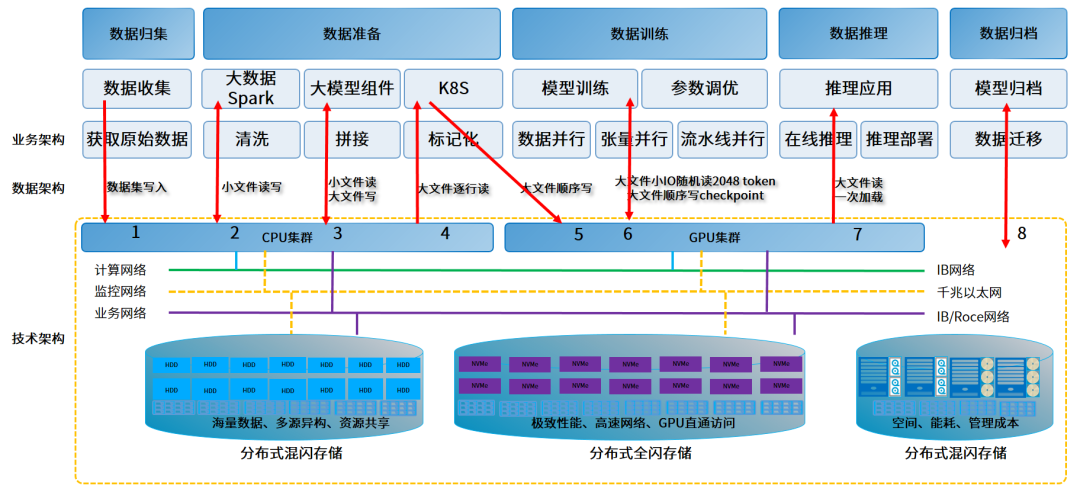
数据预处理,效率提升一倍。智算中心以元脑NF5266G7存储服务器搭建分布式混闪资源池,可以大幅降低AI大模型数据预处理过程中的资源争用并提升系统吞吐量,PB级数据预处理效率提升一倍。NF5266G7在2U空间可搭配高性能的CPU,24块存储大盘和8块NVMe(U.2或E1.S接口),支持最高128个算力核心,计算性能提升60%,带宽可达百GB网络,可提供HDD:SSD数量3:1,采用NVMe作为缓存,大幅提升海量异构数据的处理效率,满足预处理阶段PB级数据清洗、过滤等过程中的大量计算和存储资源需求。
模型训练,断点续训时间缩短1min以内。智算中心采用以NF5180G7为核心的元脑服务器,构建了10PB的分布式全闪存储资源,全闪训练池存储带宽6TB/秒,吞吐量5亿IOPS,满足大规模参数和数据频繁读取写入的需求。NF5180G7作为全闪文件存储节点,在1U空间最大支持32个E1.S SSD全闪存储与CPU直连,最大限度地提高 CPU 和存储之间的吞吐量,存储带宽和IOPS超过业界平均水平33%以上,且全闪性能可伴随节点数量增加而线性增加,万亿参数模型下断点续训时间可以实现在1min内,90天的单训练周期GPU等待时间从7天减少到1天。
数据归集,TCO降低12%。智算中心基于元脑服务器NF5476G7搭建了50PB的海量混闪资源池,实现对文本、图像、视频及其他各种数据类型的高效归集。NF5476G7单节点支持PB级别以上存储容量,单PB 大文件读(TCP)≥5GB/s性能,不仅保障海量视频流、图片、文件等原始数据存储需求,提升访问速度和效率,还拥有极高的存储性价比。
同时,基于元脑服务器打造的多层存储方案还具备高可用、智能运维、高安全等特点,通过智能诊断、设备秒级一键报修、内存故障预警MUPR2.0、硬盘寿命预警等技术,显著降低系统故障率,提升存储的持续运行能力。
如今,该智算中心已形成了高效的数据流转能力,大幅降低了GPU计算空闲时间。随着AI时代数据中心计算资源的持续增长,浪潮信息将与更多智算中心持续深入合作,解决大规模AI基础设施建设面临的计算、存储、网络等系统问题,推动AIGC在千行百业的落地与应用。

 第八代服务器
第八代服务器















