智能时代,内存系统需要更大容量和更高带宽以满足算力需求,但GPU等AI加速器的内存容量(HBM)增长缓慢,导致存算失衡,放缓了大模型落地与创新速度。为解决这一难题,浪潮信息推出元脑服务器CXL内存池化方案,以软硬件协同设计理念,灵活扩展内存容量,提升GPU利用率,降低访问延迟。在AI推理场景下该方案可将内存容量和带宽提升一倍以上,大幅提升GPU利用率,缩短推理时间,全面释放GPU算力。目前元脑服务器CXL内存池化方案已经在元脑第七代和第八代算力平台全面适配优化,满足客户AI推理、EDA仿真、向量数据库、内存数据库等场景对于高内存容量和带宽需求。
元脑服务器CXL内存池化方案以内部高性能CXL交换单元为核心,解耦重构服务器存储架构,实现内存资源重组与异步迭代,灵活扩展内存容量和带宽;创新设计内存管理引擎,灵活配置调整系统拓扑方案,实现内存资源按需扩展,提升数据中心内存资源和GPU利用率,降低数据中心存储机柜空间和能耗占用;同时基于元脑KeyarchOS服务器操作系统集成智能化内存分层功能,自动识别、迁移、监控冷热数据,实现内存细粒度分层应用,大幅提升池化内存应用性能。元脑服务器CXL内存池化方案不仅显著提升了计算资源利用率和应用吞吐量,还避免了高成本的内存硬件升级,为行业提供了兼具高性能与成本效益的创新解决方案。
破局存算失衡 CXL内存池化面临应用挑战
AIGC时代的到来,在推动算力需求激增的同时,也推动内存系统向更大容量、更高带宽演进。但GPU等AI加速器的高带宽内存(HBM)容量增长缓慢,直接导致“算力”和“存力”之间的差距越来越大,放慢了智能创新的速度。
CXL作为一种开放高速互连标准,以更大内存容量和更好的内存利用效率,有望解决CPU与设备、设备与设备之间存算差距,为化解“内存墙”问题提供新的解决方案。借助CXL技术,用户能够将不同属性和类型的内存资源进行池化,实现内存与计算的解耦,构建跨服务器共享的大规模、低成本内存池。这一技术不仅支持按需动态配置内存资源,还能打造更高效、可扩展的数据中心存储架构,显著提升计算效率并降低成本。
然而,CXL内存池化技术在实际应用中面临着工作负载适应性、内存管理复杂性、系统稳定可靠性、多级内存管理等诸多挑战,影响了该项技术在数据中心的推广应用。
CXL在内存池化上面临的主要挑战:一是工作负载适应性,不同的工作负载对内存的需求和使用模式不同,如何确保内存池化技术能够适应多样化的工作负载,按需调节内存容量和带宽,是亟待解决的问题;二是内存管理复杂性,数据中心存在内存资源碎片化的问题,这导致内存池整体利用率偏低,甚至在极端情况下,即使内存容量充足,但由于碎片原因无法分配出连续的足够大的内存块。内存池化技术需要复杂的内存管理机制来确保内存资源的有效分配和回收,尤其在多主机共享内存池的情况下,如何确保内存数据的一致性和安全性成为技术实现关键;三是系统稳定性及可靠性,尤其在多主机内存共享场景下,硬件或软件故障可能会导致整系统崩溃或数据丢失。因此,系统需要具备强大的容错能力,能够在出现故障时保持正常运行。
此外,CXL内存池化虽然能弥补DDR内存与SSD存储层级间的鸿沟,提供更大的带宽及更高的容量,但其访问延时比DDR内存增加2倍以上,这也带来了多级内存细粒度管理的问题。在传统大内存应用程序中,当DDR内存被完全占用,系统就会开启内存回收机制,数据会被换出到硬盘甚至丢弃,即使后续分配的内存会被频繁访问,也只能将数据分配至速度较慢的其他类型内存中,导致应用整体的运行时间大幅延长。因此从传统存储层次结构演进为新型存储结构过程中,系统增加CXL内存池化后如何平衡带宽收益及延时裂化成为应用程序是否能有性能收益的关键因素。
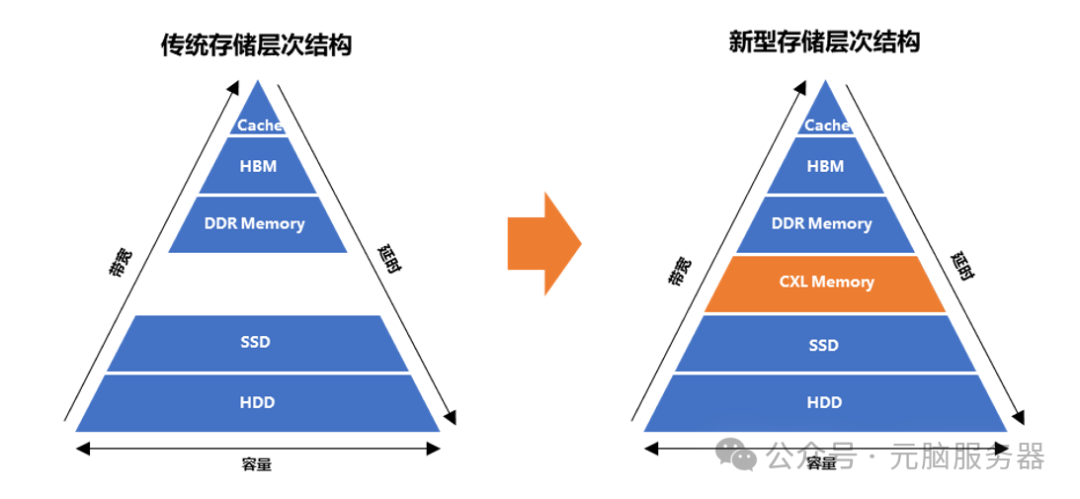 存储层次结构
存储层次结构
因此,实现大规模内存池化,针对不同的应用场景下不同的计算需求,择优选取合适的存储空间进行存储和数据处理,充分发挥系统数据处理性能,均对系统硬件架构设计及操作系统深度优化均提出了更高的挑战,需要软硬件协同设计才能真正发挥CXL的技术优势。
软硬协同实现CXL内存池化
自2019年CXL协议推出以来,浪潮信息持续进行CXL技术研究和探索,基于CXL内存池化方案,通过硬件架构创新与软硬协同优化,研发了系列内存池化原型系统,灵活扩展系统内存容量和带宽,实现内存细粒度分层管理,满足客户大内存工作负载场景需求。
面向单机系统内存容量及带宽无法满足当前应用需求的问题,浪潮信息自研了CXL内存远端扩展原型系统,在百纳秒级访问延时的条件下,系统内存容量和带宽扩大一倍。同时内存扩展产品覆盖多种形态,包括业界最大单卡扩展规模的CXL内存扩展卡(单卡支持8 DIMM扩展)、支持DDR4/DDR5 DIMM扩展方案、自研E3.S CXL内存模组,满足客户不同场景应用需求。
 CXL内存远端扩展模组
CXL内存远端扩展模组
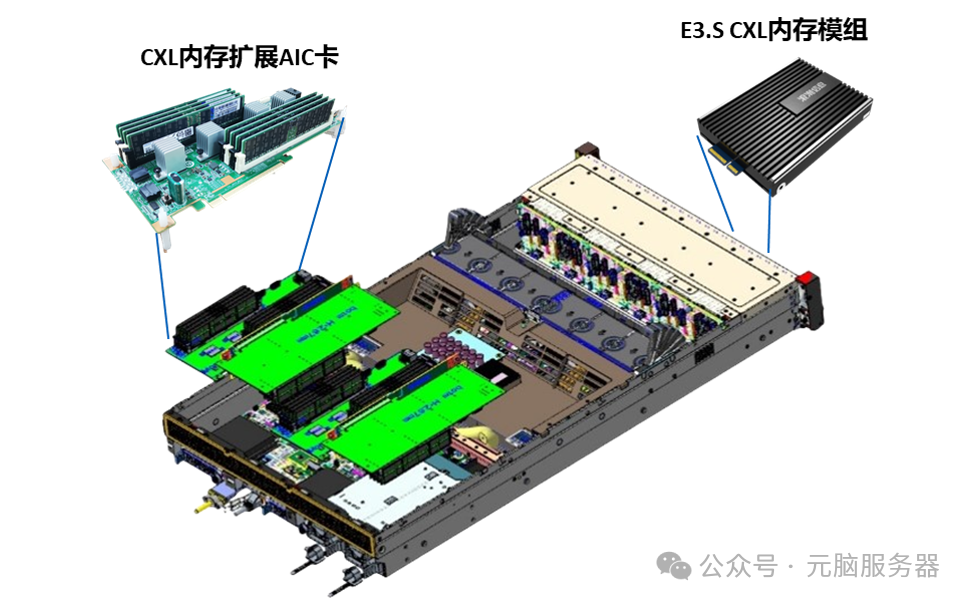 CXL内存远端扩展原型系统概览
CXL内存远端扩展原型系统概览
为解决当前数据中心面临的内存资源碎片化及运行水位过低的问题,同时进一步提升内存容量和带宽,浪潮信息创新大规模内存资源解耦重构技术,开发并完成了内存池化原型系统,以CXL互连为核心,重构了服务器架构及内存层次结构;通过内存池化管理引擎,基于软件定义的方式灵活调用分配内存资源,实现多主机内存共享。目前,单系统最大能扩展到16TB内存资源池,相比传统服务器内存容量和带宽均扩大2倍,满足AI计算、向量数据库、内存数据库多场景应用需求。
 CXL交换机及内存资源池
CXL交换机及内存资源池
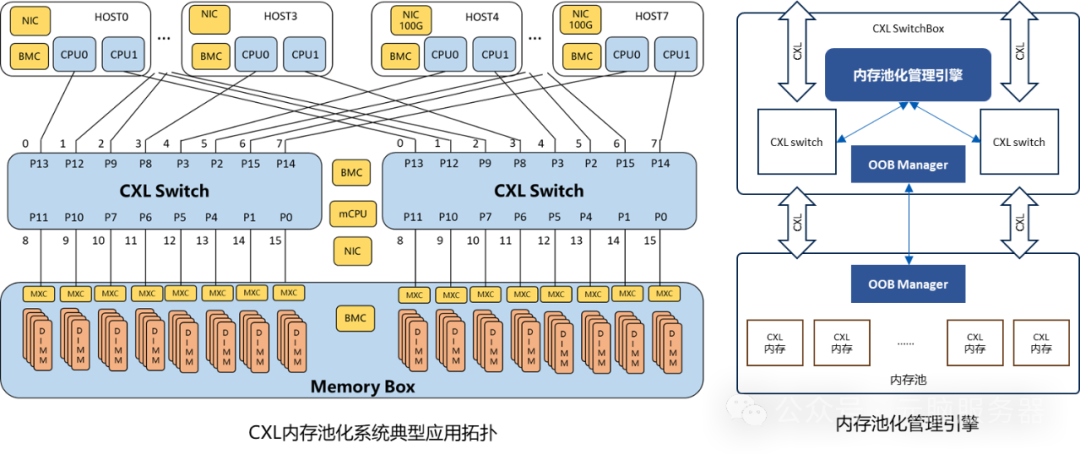 内存解耦池化原型系统总体架构
内存解耦池化原型系统总体架构
 内存解耦池化原型系统概览
内存解耦池化原型系统概览
在硬件层面实现内存池化的基础上,浪潮信息在软件层面针对内存分层机制进行了深度优化,通过元脑KeyarchOS服务器操作系统实现内存细粒度分层管理,其架构主要包含:
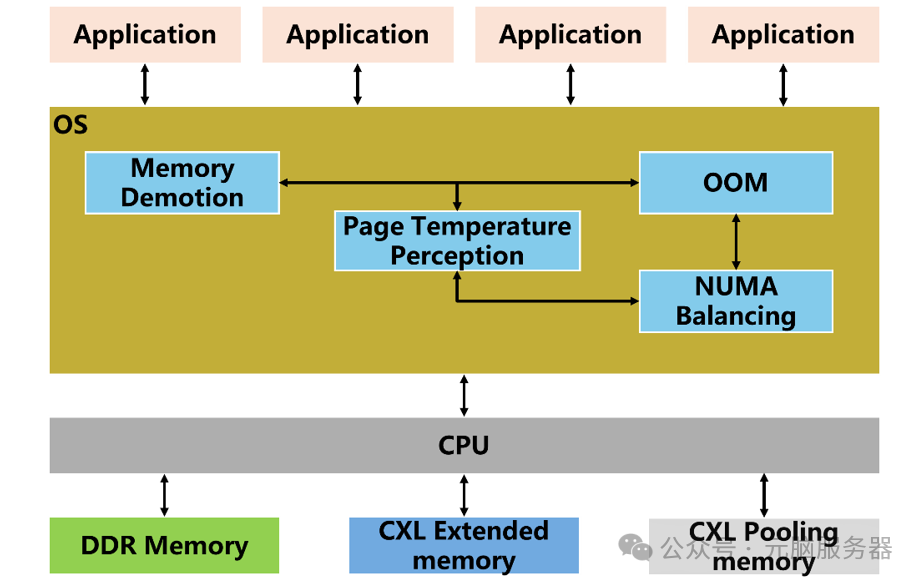 基于元脑KeyarchOs服务器操作系统的内存分层架构
基于元脑KeyarchOs服务器操作系统的内存分层架构
Page Temperature Perception:基于NUMA balance页表扫描和提示页故障之间延迟的算法来测量系统热/冷内存页面。
Memory Demotion:将DDR内存中的冷页面降级至CXL内存。将每个CPU下的各层内存识别为单独的NUMA节点,回收机制中即将被清除的DRAM页面会被认为是“冷页面”并被迁移到其他内存层中。
NUMA Balancing:将CXL内存中的热页提升至DDR内存。设计NUMA Balancing 功能将在慢内存节点中的“热页面”提升到快内存节点内,对应快内存节点需将节点中对应大小的空闲页面移入慢内存节点内。
OOM:确保节点有足够的可用页面用于升级/降级。在回收器释放足够的内存之前,NUMA Balancing无法将热数据升级到本地节点。因此很有必要主动地在本地节点上维护一定量的空闲内存余量,系统可以在本地节点上使用异步后台回收过程,直到其可用页面总数达到设定阈值才允许新数据分配至此节点。
三大核心场景性能卓越,让AI应用“有容乃快”
经过测试,元脑服务器CXL内存池化方案在AI推理、向量数据库和内存数据库三个最重要的大内存应用场景中,均有卓越性能表现。
在智能客服、智慧园区等AI推理场景下,元脑服务器CXL内存池化方案为运行更大参数AI模型提供了更高容量和性能的内存支持。实测数据显示,使用CXL扩展内存后,应用的GPU利用率提升72%,相同数据集的推理耗时缩短35%;结合内存分层技术后,应用的GPU利用率可再次提升3.6%,相同数据集的推理耗时进一步缩短10%。
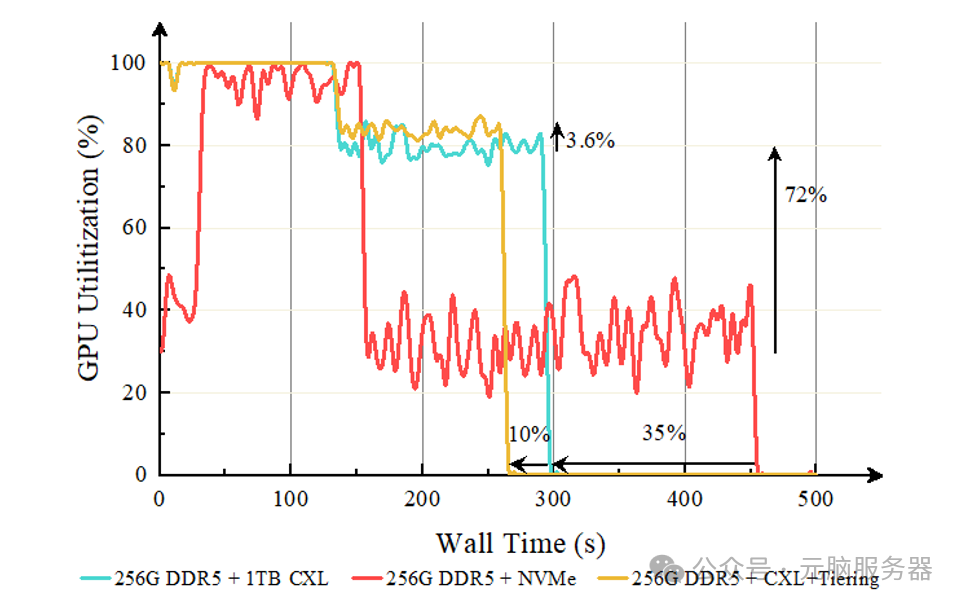 OPT 66B推理测试中GPU利用率变化
OPT 66B推理测试中GPU利用率变化
在RAG、AI制药等向量数据库应用场景中,内存带宽成为限制应用性能的瓶颈。通过使用无需修改内核和应用程序的内存分层管理软件,可充分利用DRAM和CXL存储提供的容量和带宽。相比全DDR配置,通过调整应用的DDR、CXL内存占比,应用吞吐量提升了24%。
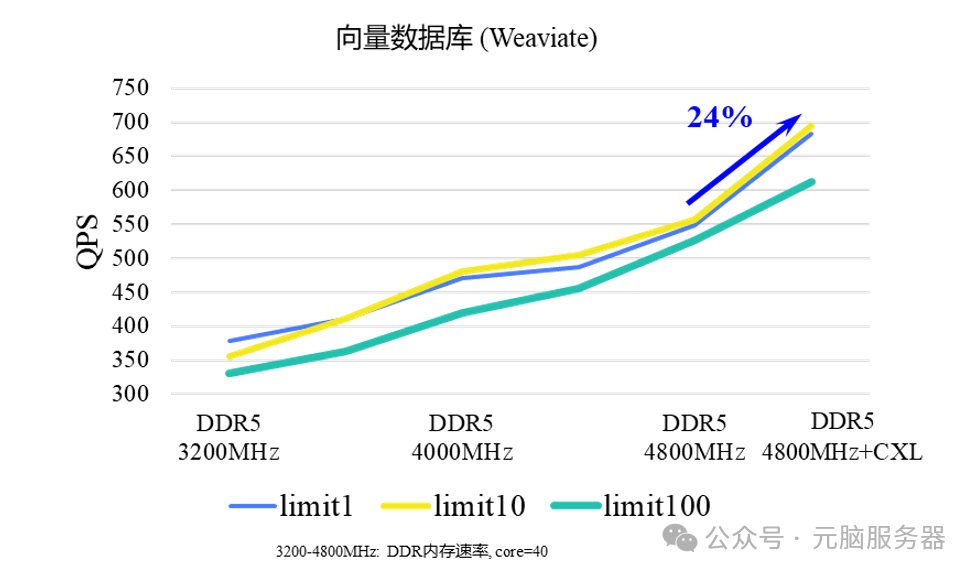 向量数据库性能测试结果
向量数据库性能测试结果
在金融交易、商业智能等内存数据库应用场景中,元脑服务器CXL内存池化方案扩展了数据库的可用内存容量,数据库吞吐量可提升92%;其内存分层功能实现了本地内存与CXL远端内存之间的冷热页面迁移,开启此功能可再提升数据库吞吐量12%,相比使用更高内存容量的内存条,性能仅低9%。
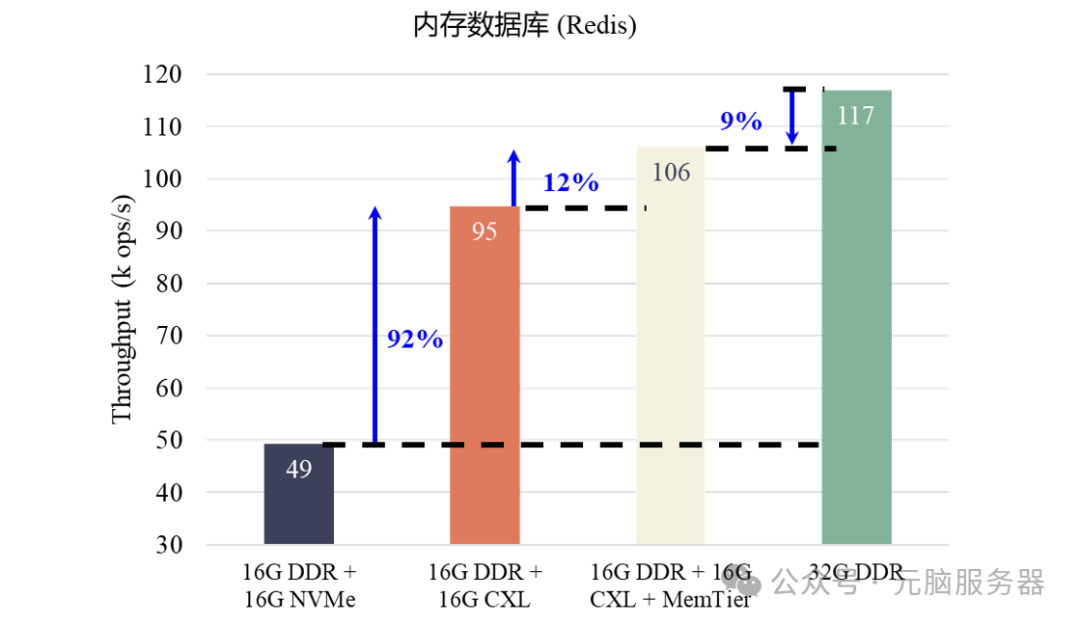 内存数据库应用性能测试结果
内存数据库应用性能测试结果
浪潮信息在CXL内存池化及分层技术的探索与实践,不仅推动了CXL内存技术的创新,为大模型、大数据等场景提供了更高效的解决方案,同时也在客观上加速了CXL的技术成熟度,为CXL在数据中心大规模应用提供了深度优化的、可验证的基础设施。在浪潮信息等厂商的协同创新下,CXL技术将在未来的计算架构中扮演更加重要的角色,让更多数据中心用户从中受益。

 第八代服务器
第八代服务器















