元脑服务器第八代平台智能大升级,不惧数据中心运维三大“暴击”
日前,元脑服务器第八代算力平台全新升级服务器智能管理功能,依托数百万级服务器运维管理经验,实现服务器内存、风扇、硬盘等部件的智能运维管理,并支持10万+大规模数据中心的智能化管理,帮助用户运维团队直面大规模数据中心的“运维暴击”,为AI时代的算力基础设施提供智能、高效、安全的运维管理服务。

AI时代,数据中心正经历一场前所未有的“进化”。爆发的AI训练、推理,还有大数据分析、云计算等业务,让数据中心算力需求暴涨、能耗持续攀升,运维团队每天都在“刀尖上跳舞”——高负载、高并行的各类应用给服务器内存、风扇、硬盘带来“暴击”,稍有不慎就可能造成宕机、数据丢失甚至业务中断。同时,随着服务器规模快速攀升,数据中心运维管理每天要检测上万台服务器的运行状态,如何保证大规模设备管理平台的稳定、提升管理效率等方面也面临着重重挑战。面对数据中心运维的多重运维暴击,元脑服务器第八代算力平台全新升级内存故障预警、风扇散热控温、硬盘故障管理等智能化运维功能,并在数据中心运维管理平台方面进行了全面的智能增强。
数据中心运维的三大“暴击”
暴击一:内存资源“告急”,宕机风险步步紧逼
AI模型的训练和推理对内存的需求堪称“饕餮”。AI计算任务往往涉及大规模并行计算,对内存的使用更加密集,以GPT-3为例,其训练需要数百GB甚至TB级别的内存资源。随着模型规模的不断扩大,内存的需求还在持续增长。
内存资源不仅昂贵,还非常“娇气”。一旦出现故障,轻则影响单台服务器的性能,重则导致整个集群的崩溃。更糟糕的是,内存故障往往难以预测,传统的监控手段只能“事后补救”,无法做到“未卜先知”。
据统计,由服务器硬件异常导致的宕机中,高达74%是由内存故障引发的。内存故障可分为不可纠正错误UCE和可纠正错误CE,UCE故障可能会导致服务器立马宕机。
安全研究机构波洛蒙研究所的统计结果显示,具有一定规模的企业发生服务器宕机事件,会带来平均每分钟近9000美元的损失成本,小型企业的损失在每分钟137至427美元之间。
元脑服务器第八代算力平台全新升级的内存故障智能预警修复技术MUPR,从单端预警升级为BIOS、BMC两级防护,通过对上万台服务器故障数据的建模分析和AI模型算法的训练,实现了对内存UCE故障的精准预测和实时修复。
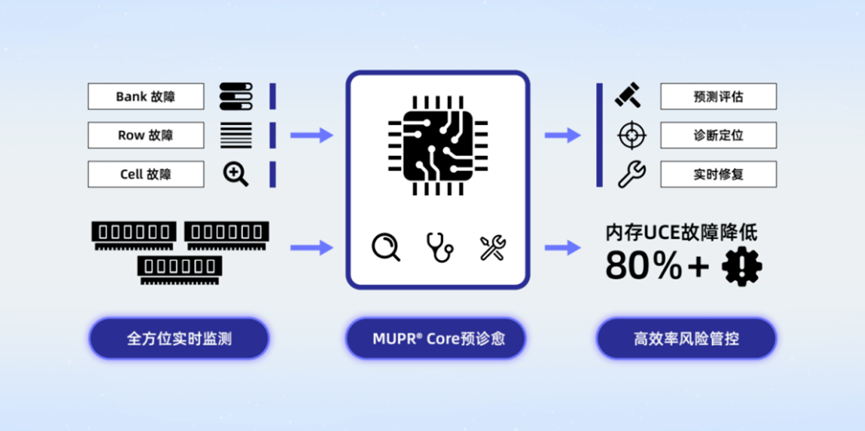
搭载了MUPR技术的元脑服务器,全天候、多方位监测服务器内存健康状态,50万台服务器级别的数据中心,内存UCE发生率按年化1%计算,MUPR技术可以有效规避80%以上的内存UCE发生,每年节省约5400万元的内存故障维护费用。
暴击二:温控压力“爆表”,开机如起飞
算力越强,发热量就越大。一台高性能的服务器功耗可能高达数千瓦,相当于几十台普通服务器的总和。而数据中心的散热系统往往“跟不上节奏”,导致服务器温度过高,性能下降甚至硬件损坏。
光听服务器开机的声音以为是“飞机起飞”。“明明刚开机,服务器内部各个部件还未完全上电,风扇转速为什么要拉满?”运维人员大为不解却无可奈何。而且,伴随着风扇的呼啸声,服务器启动“龟速”,开机时间要三五分钟甚至更久。
症结就在于,服务器传统控温策略中为了尽可能满足散热安全性要求,上电之后会以最大配置的方式来进行风扇速度调节,而此时BMC Linux系统尚未启动,热量传感器数据无法采集,导致风扇满载状态会持续较长时间,带来能耗、噪音的攀升和稳定性的降低。而且,为了避免开机过程中散热风险,一般会设置等待BMC Linux系统启动完成后再启动POST过程,导致服务器从AC上电到进入OS的时间被拉长。
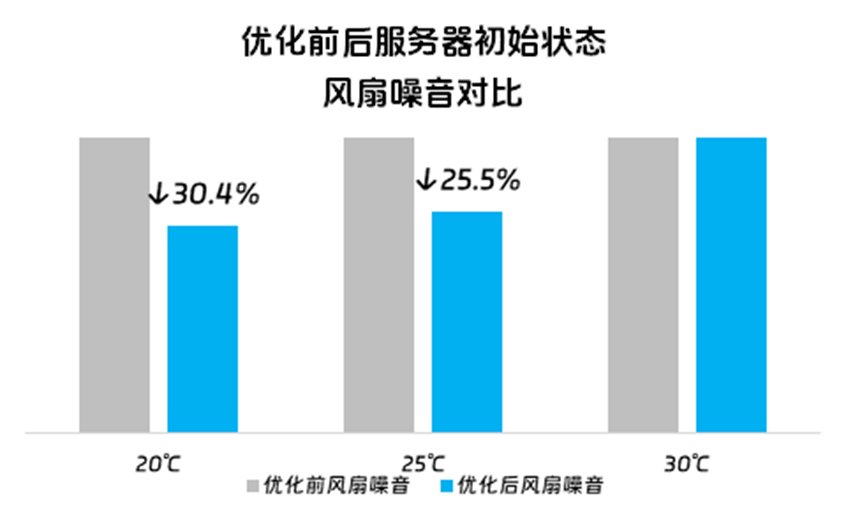
浪潮信息首创服务器开机3秒智能控温技术,通过BMC Linux/RTOS异构双系统并行管理技术,实现了上电即开机,开机时间缩短一半以上。同时,该技术通过实时感知环境温度,动态调控风扇转速,噪音比优化前最大下降30.4%,开机功耗也可大幅降低。
暴击三:硬盘故障“频发”,数据安全岌岌可危
AI时代,数据就是“命根子”。然而,随着数据量的爆炸式增长,硬盘的故障率也在不断上升。一块硬盘的故障可能导致数TB的数据丢失,而数据恢复的时间成本和经济成本都高得惊人。
某互联网大厂的数据中心4年内的29万次硬件故障中,硬盘故障占比高达81.84%。一旦硬盘故障,就会导致阵列降级,读写性能下降,期间还会存在二次掉盘导致的数据丢失风险。虽然传统存储有RAID、副本等机制,但是数据重建过程中要使用大量IO资源,而且重建时间很长,往往以天计算,这会对业务连续性造成严重影响。
传统的硬盘监控手段往往只能“亡羊补牢”,无法提前预警。更糟糕的是,硬盘故障的排查和修复需要大量人力,运维团队常常疲于奔命,类似于中医“治未病”理念的准确预测成为硬盘真正“硬”起来的最优解。
根据当前技术规范,服务器系统可提取的硬盘参数大约60多种,这是磁盘故障判断的基础。浪潮信息的工程师们选择采用AI算法技术来建立硬盘的失效预测模型。模型累计分析了超过300亿条故障特征数据,引入GAN、XGBoost、PCCs算法,基于567种预处理参数的近百种模型组合,以匹配不同型号、不同厂商的硬盘,最终实现最优的失效模型建模。
目前,元脑服务器第八代算力平台已经实现HDD故障预测、SSD寿命预测,提前14天预测风险盘,故障预测准确率超95%,误报率小于1%。

设备规模爆发,大规模数据中心运维面临新挑战
一方面,数据中心运维的三大“暴击”依旧需要面对,另一方面,AI时代的算力需求,让数据中心的设备规模快速攀升,基础设施运维管理面临全新挑战。
在大规模数据中心,随着业务量的快速增长,服务器数量爆发式增长,设备规模从最初的1000台逐渐增加到10万台,规模扩大了100倍,涵盖了不同年代和厂商的服务器、存储、网络设备等,设备种类多,内存、电源、硬盘、风扇等各类故障发生的不确定性大。
以拥有10万+设备的大规模数据中心为例,每日产生高达近30TB的设备运行状态、亿级监控指标、数千条告警推送等,如何秒级反馈海量并发需求,保证管理平台稳定运行,如何避免将每秒近千条的大规模设备告警风暴强塞给客户,进行根因定位并避免误报、漏报,这些挑战正伴随服务器、存储和网络设备规模的持续增长,成为超大规模数据中心管理亟待解决的难题。
在最近的一项调查中,57%的数据中心所有者表示,他们会相信人工智能模型来做出运营决策,借助智能平台来简化日常运维——这比上一年增长了近20%。
面对数据中心大规模的设备运维管理需求,浪潮信息数据中心基础设施管理平台结合在数据中心大规模IT设备运维实践经验,通过统一接口、协议,能够纳管多达400种不同厂商、不同型号的服务器、存储、网络等机型,设备规模最多可达10万台,不仅创造了金融行业单一数据中心带外管理的最大纪录,还实现了数据中心基础设施全生命周期管理,整体运维效率提升两倍,为超大规模数据中心运维提供智能均衡调度、实时精准告警等管理功能;同时在智能化方面,管理平台通过智能均衡作业调度平台,能够在秒级内处理超大规模数据中心亿级实时并发运维管理数据,并基于自研的告警管理框架,实现5秒内响应上千条告警风暴,显著降低告警误报与漏报的风险。

目前,元脑服务器第八代算力平台和基础设施管理平台的全新智能升级,已在海内外收获了广泛的认可,为全球互联网、金融、通信、IT、教科研等用户的数据中心,提供了数字化、智能化的运维服务,保障数据中心业务安全、稳定地运行。
未来,随着AI技术的进一步成熟,数据中心的运维工作将从“人力密集型”持续向“技术密集型”转型。浪潮信息将以技术创新为驱动,助力数据中心在AI时代“乘风破浪“,为基础设施的数智化转型提供更加智能、高效、稳定、可靠的算力产品,加速智能时代的到来。
-
2025-03-06
-
2025-03-05
-
2025-03-04
-
2025-02-27
-
2025-02-26