数据质量决定了大模型微调的上限,但人工生成问答对成本高、效率低,难以满足大规模微调需求。因此,结合自动化工具与大模型能力,构建低成本高效数据生成管线成为关键路径。目前,从高性能模型中获取微调数据已成为行业普遍采用的一种策略。然而,由于自动化工具并未广泛普及,该策略在企业用户场景中应用较少。不过,大模型技术与服务的快速发展正在不断为高质量数据生产创造新的可能性。
■ AIGC业务数据:从海量到专业的瓶颈
利用千亿参数级大模型(如Deepseek-R1-671B)的输入输出能力,可以批量生成高质量微调数据。具体方法包括:通过模板批量生成多样化问题(如“请解释电磁感应现象,并举例说明其应用”),或从公开语料库(如维基百科、学术论文)提取关键段落作为提示词。生成回答后,通过自洽性校验(如多次生成同一问题的答案并交叉验证)或规则过滤(如剔除无效输出)提升数据质量。理论上,单台高性能服务器每日可生成上百万tokens的数据,这些数据能显著提升学生模型在指定领域的微调性能。然而,这种工业化生产模式虽解决了数据量问题,但如同原油需要精炼,原始数据必须注入专业价值才能驱动模型进化。
■ 2种核心方法增强AIGC数据输出质量
▶ RAG驱动的动态数据工厂,增强数据领域相关性
使用领域知识文档构建RAG知识库是提升大模型输出领域相关性的有效手段。通过整合特定领域知识,模型生成的内容将更贴合实际场景,从而增强模型的实用性和准确性。这种方法已广泛应用于医疗、法律、金融等行业,且效果显著。此外,该方法也适用于大规模微调数据生成,通过RAG知识库的形式将领域知识嵌入到微调数据中,可以显著提升数据的领域信息含量和准确性。
从工程实践角度看,RAG系统的检索效率较高,不会显著增加微调数据生成系统的整体耗时,也不会对生成效率产生负面影响。该方法的主要工程量在于如何整合RAG系统与大模型推理服务,例如开发一个具备RAG知识库检索能力的大模型服务接口,并通过相应方法或系统接入大模型以获取微调数据。其效果可理解为,接入RAG检索能力后,模型生成的每条数据质量都将显著提升。
这种方法的潜在好处是:微调后的领域模型在构建应用时通常会结合RAG系统使用,需要将RAG返回的检索内容准确融入到模型输出之中。当微调数据结合高性能大模型和RAG反馈结果时,这种“准确性”会隐含在微调数据中,被学生模型获取后,可以提升模型微调效果。
▶ 使用Prompt工程方法进一步优化数据格式质量
通过Prompt工程与后处理控制大模型输出也是一种有效方法。Prompt工程通过设计精准的指令引导大模型生成高质量数据,用户可指定输出的结构、格式、风格。其优势在于灵活便捷、成本低且可复用性强,能高效生成符合用户需求的数据。
在数据生成过程中,使用Prompt工程方法有多种途径。最简单的方式是参考大模型输入结构和内容的调整方法,这可以在一定程度上提升输出效果。例如,在生成产品评论时,可以要求“优点-缺点-总结”的结构;在生成法律文本时,可强调正式严谨的表达。此外,要求给出输出示例、特定语言的编码、原因或解释等,也属于此类方法。在此基础上,当前一些针对Prompt优化的研究方向值得关注。例如,通过模型输出数据反推并优化输入数据,或利用大模型生成相关输入等方法,这些方法在利用大模型生成高质量数据方面具有实践验证价值。
此外,Prompt工程方法还可以与RAG知识库联合使用,进一步提升领域微调数据的质量。目前已有技术实现了RAG知识库信息与Prompt的协同优化,这些技术对提升大模型输出的符合用户预期的效果有一定帮助,但尚未大规模工程化落地。
■ 利用思维链数据提升模型逻辑推理能力
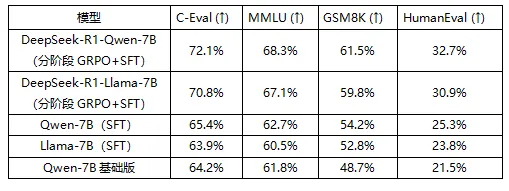
以DeepSeek-R1模型为例,介绍一种新的数据生成方式——DeepSeek-R1具备思维链推理能力,能够输出带有详细推理过程的数据,这些数据对于提升模型的逻辑推理和问题解决能力至关重要。思维链信息通常体现在“reasoning_content”字段中,展示了模型从输入到输出的思考路径,相比传统模型直接生成的结果,提供了更丰富的语义和逻辑关系,有助于模型的深度学习和能力优化。
此外,R1模型的思维链与模型输出分开,而R1蒸馏模型的思维链则直接嵌入输出中,这为微调提供了两种策略:一种是保留思维链信息,另一种是仅利用输出内容(推理结果)。
保留思维链信息:将“reasoning_content”与“content”拼接作为微调数据输出,可为模型提供全面的上下文信息,帮助其学习复杂的推理逻辑。但其缺点是数据量大,增加训练成本,并且可能引入冗余信息,影响学习效率。对于R1模型,由于其思维链与输出分开,可灵活利用“reasoning_content”字段进行微调;而对于R1蒸馏模型,其输出已包含思维链,可直接用于微调,简化数据处理流程。
舍弃思维链信息:仅保留推理结果“content”作为微调数据的方法,数据更加简洁,降低训练成本,并且可避免无关信息干扰。但缺点是模型无法学习完整推理过程,可能限制逻辑推理能力提升,尤其在需要多步推理的任务中效果不佳。
综上所述,大模型微调的数据实践是一个多维度且关键的环节,对模型的实际应用性能起决定性作用,需要综合考虑多种因素和方法,不断优化数据生产与处理流程。无论是借助RAG系统增强领域相关性,还是通过Prompt工程优化格式合规性,本质上都是将业务逻辑转化为高质量数据的过程。
未来,随着AIGC技术与思维链推理的深度结合,数据生成体系将进一步突破规模化与专业化的瓶颈,推动垂直领域模型从“能用”向“好用”跃迁。对企业而言,构建数据驱动的微调闭环不仅需要技术投入,更需建立业务与数据的双向映射机制。唯有以高质量“原油”为基石,才能真正释放大模型在专业场景中的价值潜力。

 第八代服务器
第八代服务器