
 第八代服务器
第八代服务器问题描述
用户在使用服务器搭配Linux系统,比如红帽、CentOS,有时会遇到message中有EDAC内存报错,但是在主机的BMC的事件日志中并未发现内存错误。
例如下面某客户反馈的日志:
Feb 4 21:00:06 localhost kernel: EDAC MC6: 1 CE memory read error on CPU_SrcID#3_MC#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9a97c19 offset:0xac0 grain:32 syndrome:0x0 – err_code:0101:0091 socket:3 imc:0 rank:1 bg:1 ba:1 row:6cb5 col:2f8)
涉及范围
硬件:M5、M6平台服务器
软件:Linux系统,诸如RHEL(Redhat)、CentOS、SLES(Suse)、Ubuntu等
处理方案
将edac模块加入黑名单:
1、列出 edac 模块:

2、修改黑名单:
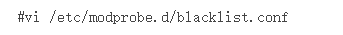
将相关的edac模块添加到文件底部
如查询的edac模块为skx_edac和edac_core那就只添加如下选项即可。

3、重启之后使用1的方式验证;
故障根因
EDAC即error detection and correction(错误检测与纠正),它是Linux系统内部的一种诊断机制。在上面的日志中,可以清楚地看出是内存读错误。
其中MC即memory controller(内存控制器)。CE则代表correctable error,是ECC内存中可以纠正的错误,相对地还有UE(uncorrectable error)。
由于寄存器默认为只读一次后删除数据,当EDAC模块比BMC先从寄存器中读取了错误后,BMC将无法读取到错误信息,所以如非客户明确需求建议禁用EDAC模块。
建议与总结
主机的BIOS/BMC有一套自己的故障处理机制,能够对CPU、内存、PCIe设备故障做统一处理。同时对内存错误有阈值和漏斗过滤控制,当计数到达阈值会触发SMI,这时BIOS会收集发生CE的内存信息发送到BMC记录到系统日志,BMC能在系统日志记录出错的内存位置和内存错误类型为可纠正错误。
OS内MCE记录的内存错误,每次出现一次可修复的ECC,BIOS就会触发一次CMCI让OS记录,没有阈值设置,也不会做内存错误隔离,会给客户造成一定的困扰。所以建议忽略OS下的内存MCE报错记录。
















